INSIGHT — INtelligent Synthesis and Generation of High-quality Test data
Realistische Testdaten ohne reale Daten
Die Herausforderung
Wer Machine-Learning-Modelle trainiert, Software testet oder datengetriebene Forschung betreibt, steht vor einem grundlegenden Problem: Es fehlt an realistischen, strukturierten Testdaten. Reale Datensätze sind oft unvollständig, unausgewogen oder datenschutzrechtlich nicht nutzbar. Die manuelle Erstellung bindet wochenlang Kapazitäten und liefert trotzdem selten die nötige Varianz und Abdeckung, besonders in sensiblen Domänen wie Medizin, Recht oder Bildung.
Die Kernprobleme
- Manuelle Datenerstellung bindet Forschungs- und Entwicklungskapazitäten über Wochen, oft ohne reproduzierbares Ergebnis
- Reale Daten unterliegen häufig dem Datenschutz (DSGVO) und können nicht frei geteilt oder vervielfältigt werden
- Bestehende Tools decken meist nur einen Ansatz ab, entweder regelbasiert oder ML-gestützt, selten beides
- Kein standardisierter Prozess für reproduzierbare, teamübergreifende Datengenerierung
- Relationale Zusammenhänge wie Foreign Keys und Kardinalitäten gehen bei synthetischen Daten oft verloren
Die Lösung
INSIGHT ist ein IFB-Hamburg-gefördertes Forschungsprojekt von AKARA Solutions und HITeC e.V. (Universität Hamburg). Im Rahmen des Projekts entsteht eine webbasierte Plattform zur Erzeugung synthetischer Testdaten. Statt eines einzelnen Ansatzes vereint die Plattform drei komplementäre Use Cases unter einer Oberfläche.
Unsere Lösung umfasst
- Mockup, Regelbasierte Generierung mit LLM-Assistenz: Für frühe Projektphasen, in denen noch keine realen Daten vorliegen. Nutzer definieren Tabellenstrukturen, Datentypen und Constraints wie Primary Keys, Foreign Keys und Unique-Bedingungen. Aus über 90 konfigurierbaren Datentypen generiert die Plattform beliebig große, relationale Datensätze. Ein integrierter LLM-Chat-Assistent unterstützt dabei von der Schemadefinition bis zur fertigen Datei.
- Replication, Statistische und KI-gestützte Vervielfältigung: Wenn reale Daten vorhanden, aber zu wenige oder nicht teilbar sind. Zwei Verfahren stehen zur Wahl: GaussianCopula lernt statistische Verteilungen und Korrelationen einzelner Tabellen. Für komplexe relationale Datensätze mit mehreren verknüpften Tabellen kommt ClavaDDPM zum Einsatz, ein Diffusion-Modell basierend auf aktueller Forschung (NeurIPS 2024), das Tabellen in topologischer Reihenfolge generiert und die referenzielle Integrität über Foreign Keys hinweg erhält.
- Reduction, Intelligentes Reduzieren: Der umgekehrte Weg: Große Datensätze werden auf repräsentative Teilmengen reduziert. Je nach Anforderung stehen drei Strategien zur Wahl: stratifizierte Stichproben für Verteilungserhalt, Near-Duplicate-Erkennung via MinHash/LSH für Deduplizierung oder FAISS-basiertes Clustering für vektorbasierte Ähnlichkeitsanalyse.
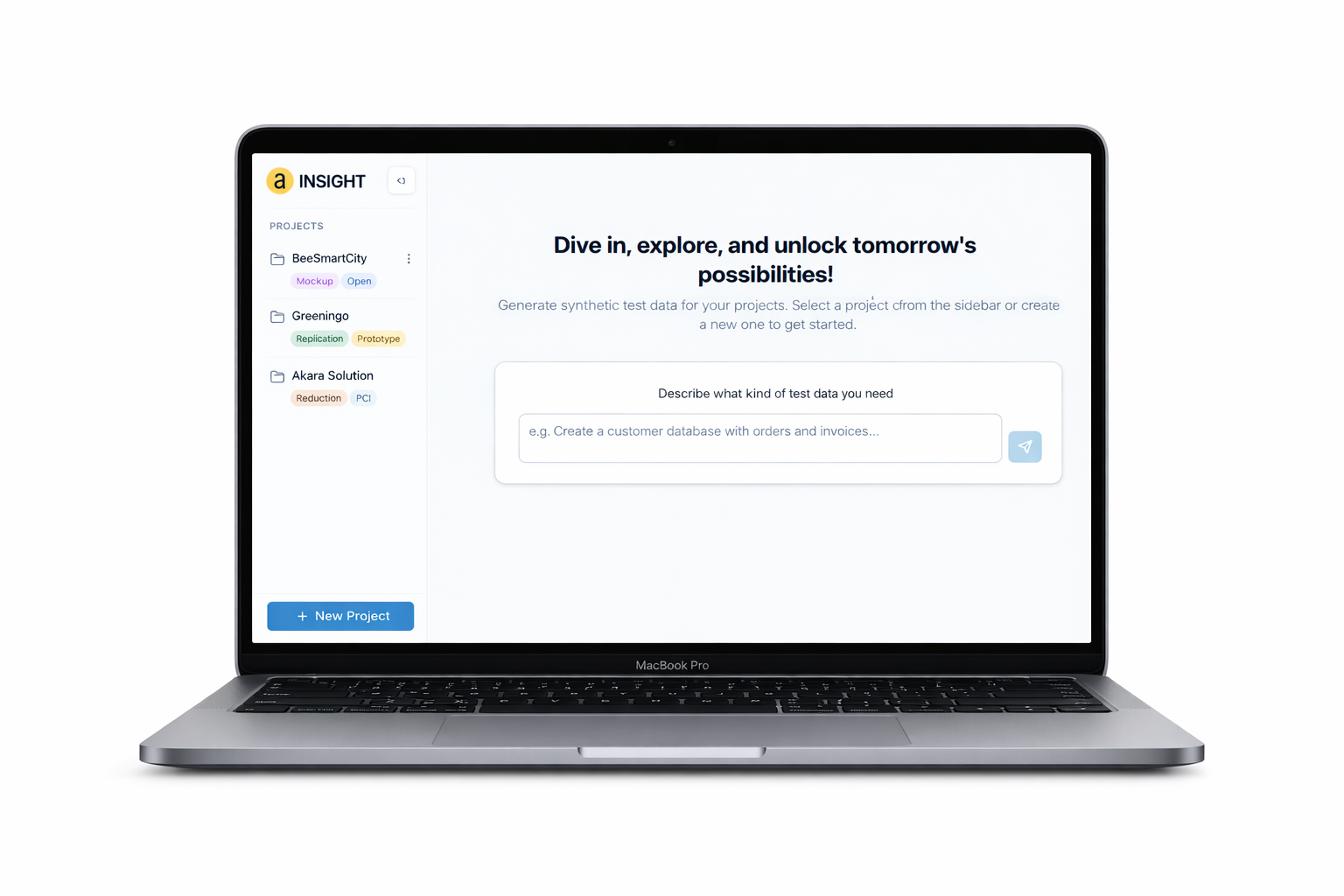
Die Ergebnisse
INSIGHT ermöglicht es, den Weg von der Forschungsidee zum validierten Datensatz deutlich zu verkürzen, mit voller Kontrolle über Struktur, Qualität und Umfang der synthetischen Daten.
Mockup
- Datensätze werden in Minuten statt Wochen erstellt, ohne dass reale Daten vorliegen müssen
- Über 90 konfigurierbare Datentypen decken domänenspezifische Anforderungen ab
- Einmal erstellte Schemata lassen sich versioniert speichern und im Team wiederverwenden
Replication
- Statistisch realistische Daten auf Knopfdruck, das trainierte Modell ist beliebig oft wiederverwendbar
- Automatisierte Qualitätsevaluierung mit Verteilungsvergleich, Korrelationsanalyse und Coverage-Metriken, visualisiert in integrierten Dashboards
- Multi-Table-Generierung mit erhaltener referenzieller Integrität über Foreign Keys hinweg
Reduction
- Große Datensätze auf repräsentative Teilmengen reduziert, mit messbarer Verteilungstreue
- Drei Strategien für unterschiedliche Anforderungen: Verteilungserhalt, Deduplizierung oder Clustering
Ähnliche Case Studies

Intelligentes Dokumentenmanagement mit KI
Von der manuellen Ablage zur KI-gestützten Dokumentenautomatisierung – ohne teure Lizenzen
Rechnungen suchen, Fristen überwachen, Belege sortieren – das frisst in vielen KMU Stunden pro Woche. Diese Case Study zeigt, wie sich mit Open-Source-Software und künstlicher Intelligenz ein vollständiges Dokumentenmanagementsystem aufbauen lässt, das Dokumente automatisch erkennt und kategorisiert
Case Study ansehen
Smart City Vernetzungsplattform
Die weltweit größte Vernetzungsplattform für Smart City Akteure
Mit über 14.750 Mitgliedern aus mehr als 170 Ländern haben wir für bee smart city eine globale Vernetzungsplattform entwickelt, auf der sich Smart-City-Experten, Kommunen, Lösungsanbieter und Forschungseinrichtungen vernetzen, Wissen austauschen und voneinander lernen.
Case Study ansehen
KI-gestützter Angebotsgenerator
Eine explorative Studie wie mit einer mehrstufigen KI-Pipeline der Weg von der Kundenanfrage zum versandfertigen Angebot auf Sekunden verkürzt werden kann — ohne die Kontrolle abzugeben
Vertriebsteams verbringen Stunden damit, Kundenanfragen manuell in Angebote zu übersetzen: lesen, zuordnen, kalkulieren, formulieren. Wir zeigen, wie KI diesen Prozess auf Sekunden verkürzen kann.
Case Study ansehen