INSIGHT — INtelligent Synthesis and Generation of High-quality Test Data
Realistic test data without real data
The Challenge
Anyone training machine learning models, testing software, or conducting data-driven research faces a fundamental problem: a lack of realistic, structured test data. Real-world datasets are often incomplete, imbalanced, or unusable due to data privacy regulations. Manual creation ties up capacity for weeks and still rarely delivers the necessary variance and coverage — especially in sensitive domains like healthcare, law, or education.
The core problems
- Manual data creation ties up R&D capacity for weeks, often without reproducible results
- Real data is frequently subject to GDPR (DSGVO) regulations and cannot be freely shared or replicated
- Existing tools typically cover only one approach — either rule-based or ML-powered, rarely both
- No standardized process for reproducible, cross-team data generation
- Relational dependencies like foreign keys and cardinalities are often lost in synthetic data
The Solution
INSIGHT is a research project funded by IFB Hamburg, developed by AKARA Solutions and HITeC e.V. (University of Hamburg). The project delivers a web-based platform for generating synthetic test data. Rather than a single approach, the platform unites three complementary use cases under one interface.
Our solution includes
- Mockup — Rule-based generation with LLM assistance: For early project phases where no real data exists yet. Users define table structures, data types, and constraints such as primary keys, foreign keys, and unique constraints. From over 90 configurable data types, the platform generates relational datasets of any size. An integrated LLM chat assistant supports the entire workflow from schema definition to the finished file.
- Replication — Statistical and AI-powered augmentation: For cases where real data exists but is too scarce or cannot be shared. Two methods are available: GaussianCopula learns statistical distributions and correlations of individual tables. For complex relational datasets with multiple linked tables, ClavaDDPM is used — a diffusion model based on recent research (NeurIPS 2024) that generates tables in topological order and preserves referential integrity across foreign keys.
- Reduction — Intelligent downsizing: The reverse approach: Large datasets are reduced to representative subsets. Three strategies are available depending on requirements: stratified sampling for distribution preservation, near-duplicate detection via MinHash/LSH for deduplication, or FAISS-based clustering for vector similarity analysis.
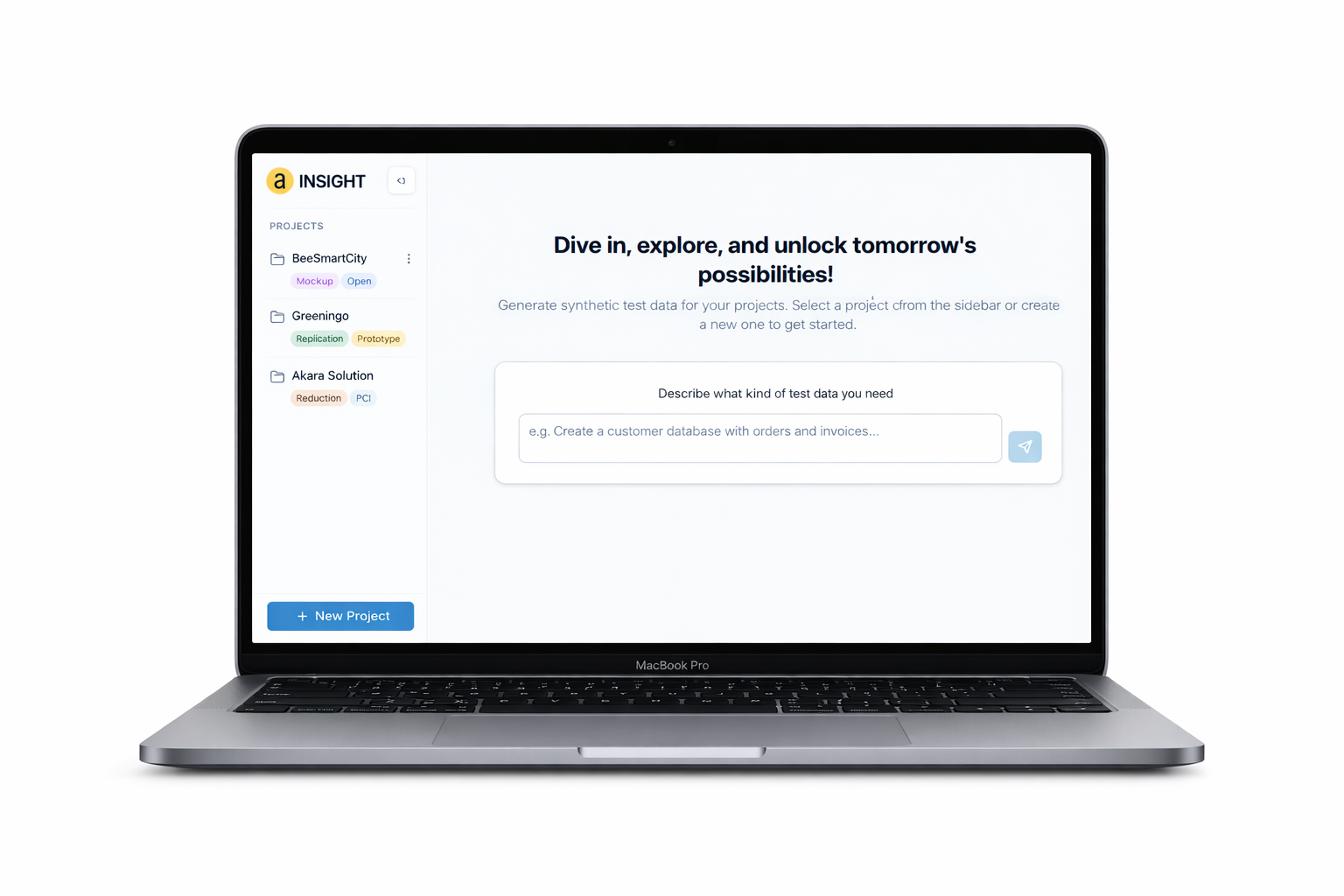
The Results
INSIGHT dramatically shortens the path from research idea to validated dataset — with full control over structure, quality, and scale of the synthetic data.
Mockup
- Datasets are created in minutes instead of weeks, with no real data required
- Over 90 configurable data types cover domain-specific requirements
- Schemas can be version-controlled and reused across the team once created
Replication
- Statistically realistic data at the push of a button — the trained model is reusable indefinitely
- Automated quality evaluation with distribution comparison, correlation analysis, and coverage metrics, visualized in integrated dashboards
- Multi-table generation with preserved referential integrity across foreign keys
Reduction
- Large datasets reduced to representative subsets with measurable distribution fidelity
- Three strategies for different requirements: distribution preservation, deduplication, or clustering
Related Case Studies

Intelligent Document Management with AI
From manual filing to AI-powered document automation – without expensive licenses
Searching for invoices, tracking deadlines, sorting receipts – this eats up hours every week in many SMEs. This case study shows how open-source software and artificial intelligence can build a complete document management system that automatically recognizes and categorizes documents
View case study
Smart City Networking Platform
The world's largest networking platform for smart city stakeholders
With over 14,750 members from more than 170 countries, we built a global networking platform for bee smart city where smart city experts, municipalities, solution providers, and research institutions connect, share knowledge, and learn from each other.
View case study
AI-Powered Proposal Generator
An exploratory study on how a multi-stage AI pipeline can shrink the path from customer inquiry to ready-to-send proposal down to seconds — without giving up control
Sales teams spend hours manually turning customer inquiries into proposals: reading, matching, calculating, writing. We show how AI can cut this process down to seconds.
View case study