
The Most Expensive Model Is Rarely the Right One
A Decision Guide for AI in Practice
Introduction

Choosing the right AI model is critical to the success of AI projects. While today's technological capabilities are enormous, many implementations fail due to avoidable mistakes. Most companies focus on prompts and data — and miss the decisive point: the wrong AI model makes everything that follows inefficient, expensive, and unreliable. Even the best prompts, architectures, and interfaces won't help if the underlying model doesn't fit the use case. You end up optimizing symptoms instead of addressing the core problem.
Why Model Selection Is a Business Decision

Choosing an AI model is not a purely technical decision — it is first and foremost a strategic business decision with direct impact on cost, profitability, and scalability [1]. Models differ significantly in quality, latency, and hallucination behavior — factors that directly affect user experience and business outcomes. Context window, data privacy, compliance, and maintenance effort play a central role in practice [11], yet are often considered too late. Anyone who wants to deploy AI as a real productivity and revenue driver — not a toy — must understand which model to use when and why, and where even a "top model" just burns money.
The Danger of the 'One-Model-for-Everything' Strategy
One of the most common misconceptions: "One AI model for everything." This strategy sounds efficient but is expensive, risky, and strategically problematic in practice. Trying to handle chatbots, specialized applications, search, compliance, and automation with a single model produces exactly what you wanted to avoid: cost explosion through overengineering, a single point of failure, governance chaos, and mediocre quality across the board. Instead of a universal solution, what's needed is a systematic decision logic that deploys different models for different purposes [1].
Goal and Target Audience of This E-Book
This e-book provides a clear compass for model selection: pragmatic, actionable, and beyond the hype. It targets developers who want to make informed technical decisions and managers who oversee AI strategies and need to understand which model choice leads to which business consequences. This guide offers orientation based on practical experience, scientific findings, and proven implementation patterns.
Fundamentals
What Is an AI Model?
Think of an AI model as a specialized computer program that learns from experience — similar to an employee who gets better at their job through practice and examples. At its core, an AI model is a system trained with specific data and algorithms to replicate human intelligence in certain domains. It can independently recognize patterns, make predictions, or derive decisions. [1] [2]
The architecture of many modern AI models is based on neural networks — mathematical structures loosely inspired by the human brain. These networks consist of interconnected layers that process and pass on information. During training, the connections between these layers are adjusted so the model performs the desired tasks with increasing accuracy. [2]
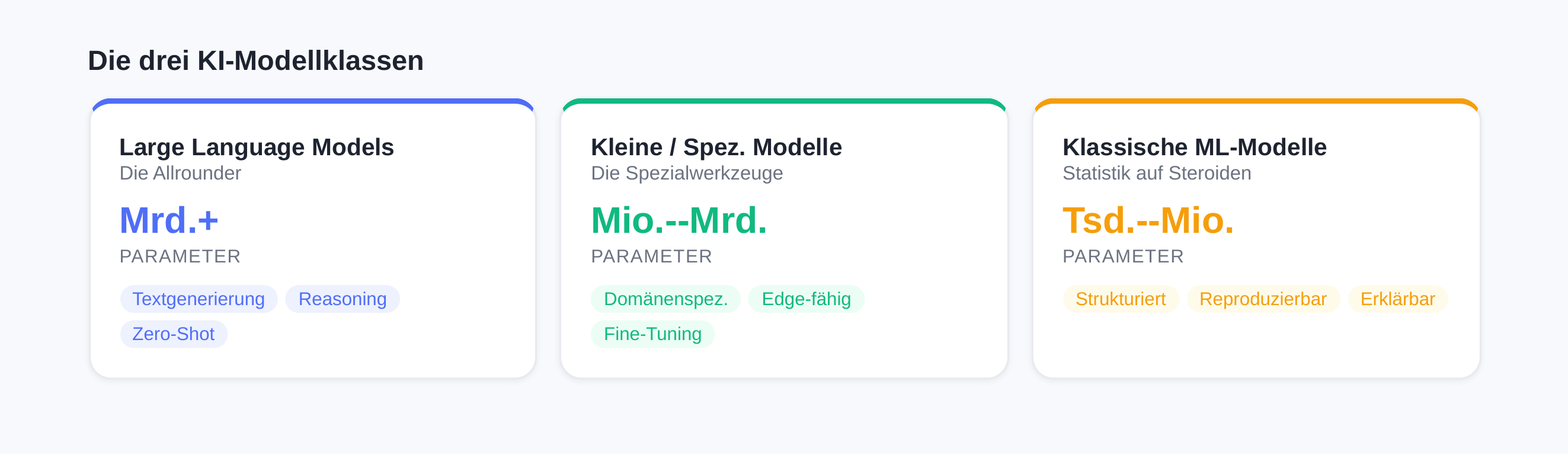
The Three Relevant Model Classes
Three model classes have established themselves in today's AI landscape, each optimized for different requirements. Understanding their strengths and weaknesses is critical for informed technology decisions.
Large Language Models (LLMs) — The "All-Rounders"

Large Language Models like ChatGPT, Claude, or Gemini have fundamentally shaped public perception of AI in recent years. These models stand out for their ability to generate text and understand natural language. [3]
LLMs were trained on massive datasets — often on a significant portion of the entire internet. They consist of numerous layers of neural networks whose billions to trillions of parameters [6] were fine-tuned during training. Their responses are based on probabilities: the model calculates the most likely continuation of a text and returns it. [3]
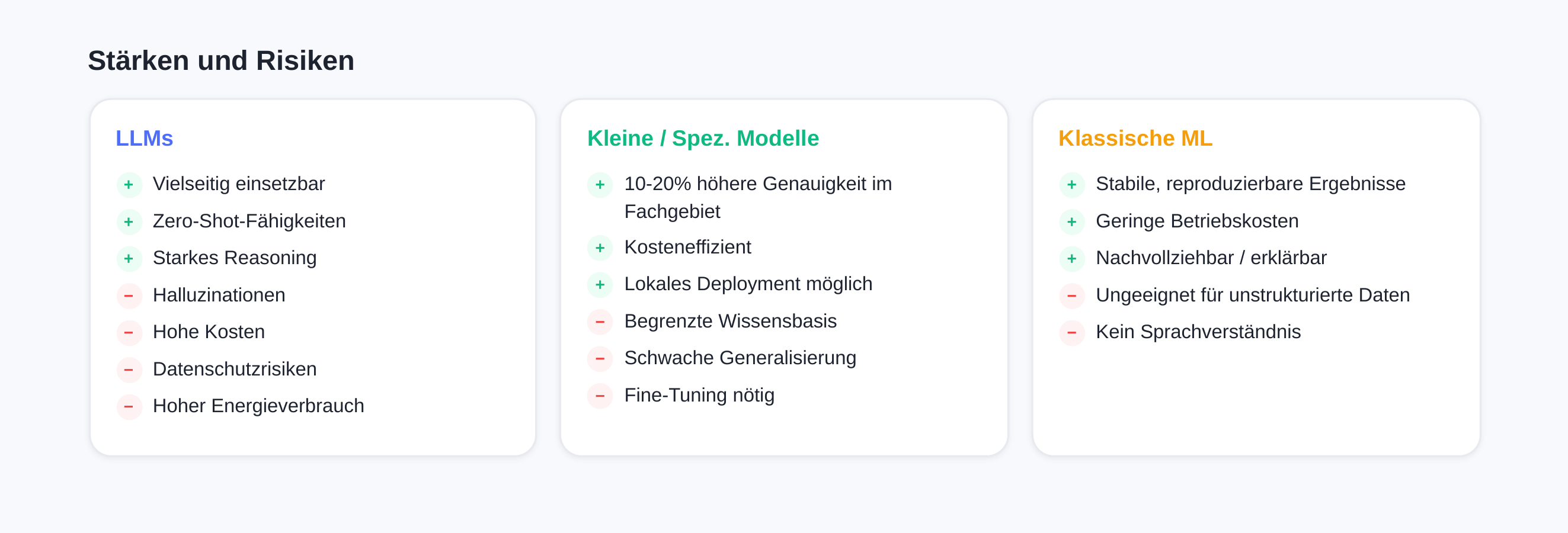
The strength of LLMs lies in their versatility. They can summarize texts, translate, answer questions, write code, and generate creative content — often without specific training for these tasks. These zero-shot and few-shot capabilities [8] make them flexible tools for a wide range of use cases. Their superior performance on complex tasks, stronger reasoning capabilities [6], and excellent generalization to unfamiliar scenarios [6] enable them to handle new tasks without adaptation. [1]
However, LLMs also bring significant challenges: they can "hallucinate" on niche topics, generating plausible-sounding but factually incorrect answers. [1] Infrastructure, training, and operational costs run into the millions [9], and API costs can become substantial at high usage volumes. [1] [5] Additional risks include data privacy concerns from cloud-based APIs [8], lack of transparency about data processing in proprietary models [9], enormous energy consumption with a high carbon footprint [7], longer response times [6], vendor lock-in with proprietary models [9], and overengineering for specific tasks [8].
Small and Specialized Models — The "Specialized Tools"
Unlike generalist LLMs, specialized AI models are designed to handle specific tasks or domains with higher precision and efficiency. They focus on clearly defined use cases — and that is exactly what makes them particularly valuable for many business and technical applications. [1]
Small Language Models (SLMs) have millions to a few billion parameters [7] and score with clear cost efficiency in development, training, and operations [20]. Their faster inference [7], better control and adaptability [8], and the ability for local deployment on edge devices [7] significantly improve data privacy and latency. For domain-specific tasks, SLMs can achieve comparable or better results through targeted training [6]. Their lower memory footprint enables operation on standard hardware such as Intel Xeon processors [10].
This category includes RAG-Heads (Retrieval-Augmented Generation) [6], domain-specific LLMs [6], or NER models (Named Entity Recognition). They are trained on domain-specific data and often achieve better results in their area of expertise than generic models. Studies show that specialized models can achieve accuracy improvements of 10–20% over general-purpose LLMs in specific use cases such as language processing or translation. [1]
The advantages are obvious: specialized models are typically smaller and require less computing power, resulting in faster response times and lower operating costs. They can also run effectively on less powerful hardware or in cloud-based environments. Companies also benefit from the flexibility to update individual modules of their AI system or add new specialized components without retraining the entire system. [1] [5]
The risks of SLMs include a limited knowledge base [7], weaker generalization outside the training domain [6], restricted complex reasoning capabilities [8], and higher customization effort due to necessary Fine-Tuning [7].
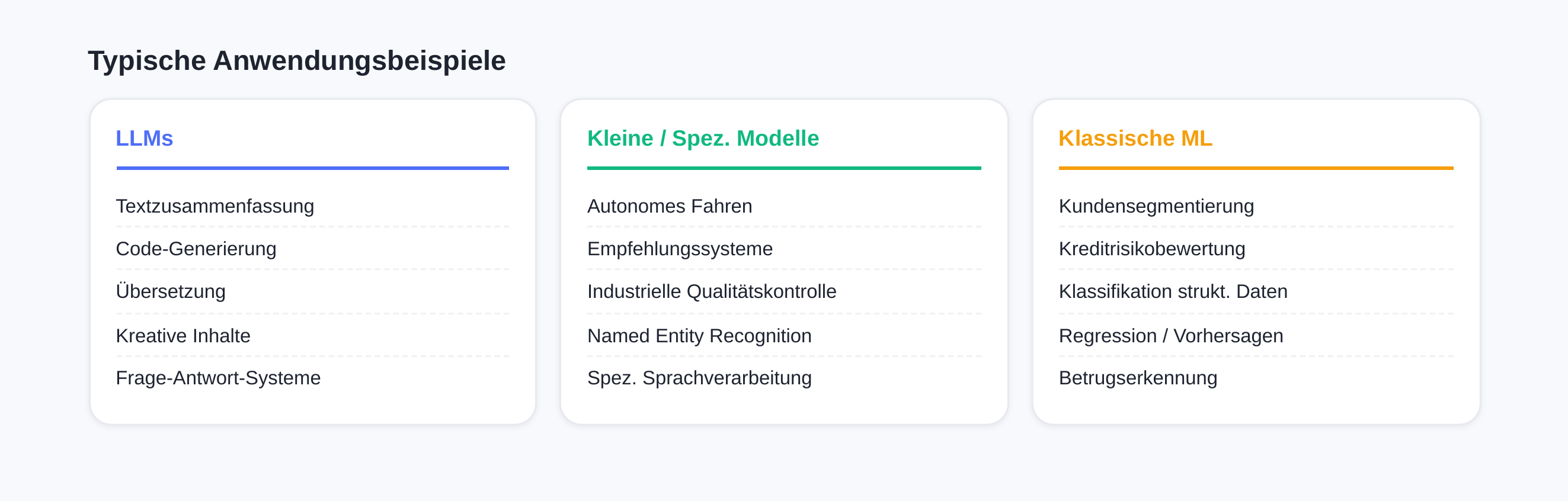
Typical application examples include autonomous driving, recommendation systems, industrial quality control, and specialized language processing. [1]
Classical ML Models — "Statistics on Steroids"
Classical machine learning models like Random Forest, XGBoost, or Logistic Regression still form the backbone of many production AI systems in enterprises. They are data-driven prediction models trained specifically on the respective use case with available data. [4]
These models excel at tasks like classification and regression — for example, analyzing structured data from spreadsheets, customer segmentation, or credit risk assessments. Their results remain stable and reproducible after training, which is essential for many business applications. [4] [5]
The major advantage of classical ML models: they can often run on standard CPU infrastructure with low operating costs. The methods have been established and well understood for years, simplifying maintainability. They also provide clear metrics and traceable results — an important factor for regulated industries. [5]
Their limitations become apparent with unstructured data like free text or images, where newer deep learning approaches are clearly superior. [1] [5]
The Five Decision Factors at a Glance
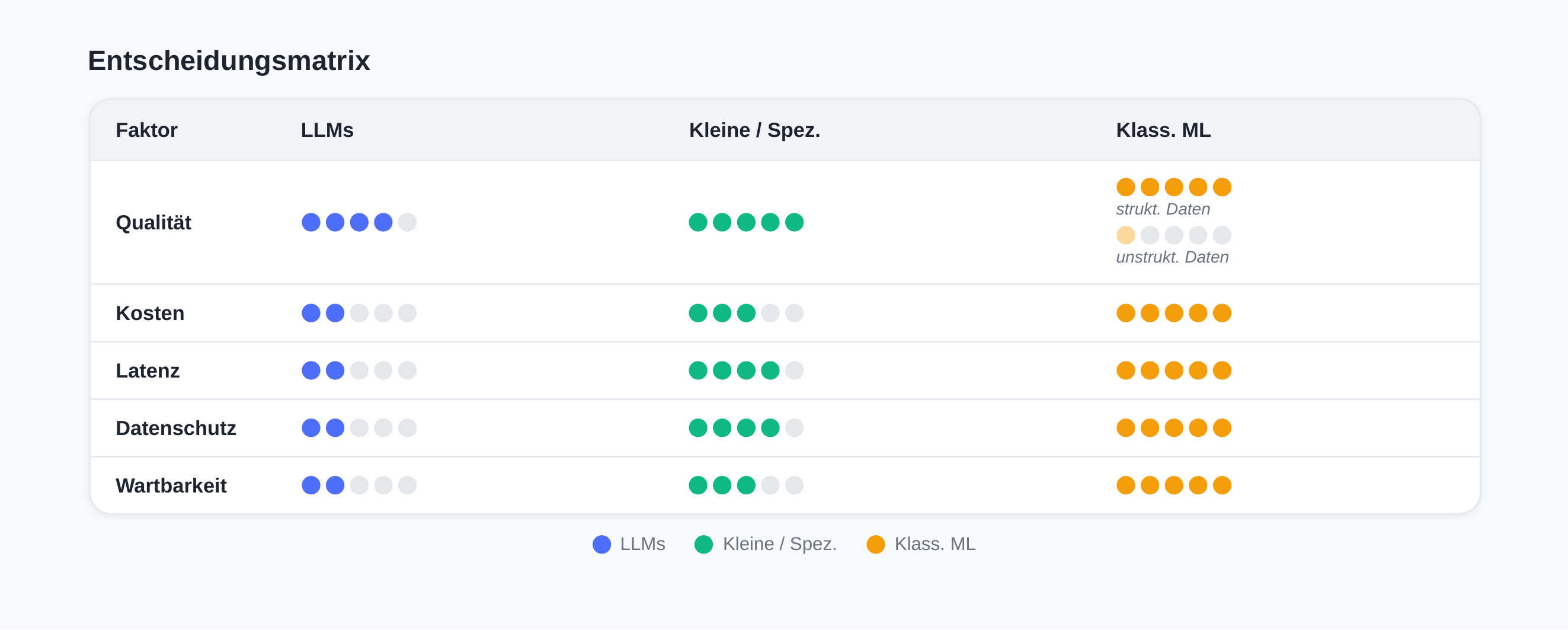
When selecting the right AI model, the following five key factors should be considered [5]. These often exist in tension with each other — optimizing in one area can require trade-offs in others.
| Merkmal | LLMs | Kleine / spez. Modelle | Klass. ML |
|---|---|---|---|
| Qualität | Sehr gut bei vielen Themen, aber nicht immer verlässlich im Detail. | Sehr gut in einem klar eingegrenzten Fachgebiet. | Sehr gut bei Zahlen und klaren Ja/Nein-Entscheidungen. |
| Kosten | Hoch (Nutzung + Infrastruktur). | Mittel. | Eher niedrig. |
| Latenz | Eher langsamer. | Meist schnell. | Sehr schnell. |
| Datenschutz | Kritisch bei Cloud und sensiblen Daten. On-Prem möglich, aber aufwendig. | Besser kontrollierbar, oft intern betreibbar. | Am besten kontrollierbar. |
| Wartbarkeit | Komplex, Verhalten ändert sich mit Versionen. | Mittel: überschaubar, aber KI-Betrieb. | Am einfachsten, bewährte Methoden. |
Conclusion: Choosing the optimal AI model is not a purely technical decision — it must account for the business context, available resources, and specific requirements. In practice, a hybrid approach often proves effective: classical ML models for structured prediction tasks, specialized models for domain-specific challenges, and LLMs for flexible language processing and generative tasks. The key is to resist the temptation of deploying the newest and largest model for every problem. A well-trained, specialized model is often the better choice — more cost-effective, faster, and more controllable. The art lies in knowing each model class's strengths and deploying them strategically.
Architecture Decisions Around AI
Architecture Questions That Change Everything
A mid-sized company invests 200,000 euros in an AI project for automated customer communication. After six months of development, the verdict: the chosen architecture doesn't match the actual need. Fine-Tuning a large language model was complex and expensive — a simple RAG solution with a standard LLM could have achieved better results. Such scenarios are far from rare [50]. The choice of the right AI architecture determines whether a project becomes economically successful or turns into a cost trap.
Prompt Engineering as a Starting Point
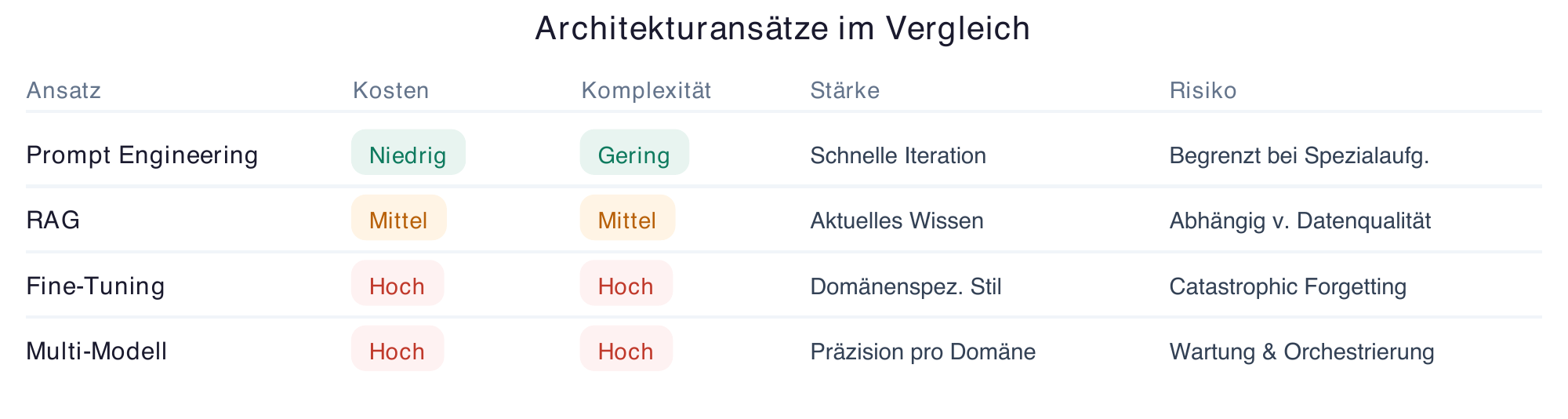
Before considering complex architectures, start with the basics: Prompt Engineering. The quality of AI results is significantly influenced by how you communicate with the model [12]. A precisely crafted prompt can often boost the performance of a standard model to the point where more elaborate approaches become unnecessary.
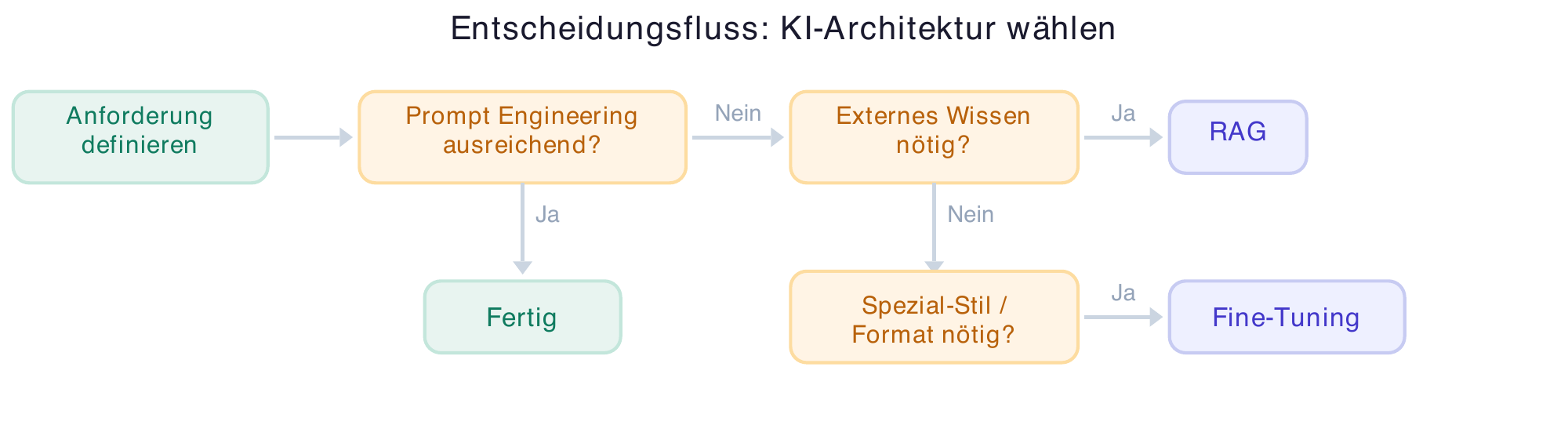
In practice, this means: first test what a well-structured prompt can achieve. Define clear instructions, provide context, and use examples for the desired output format [21]. The latest models like Claude Opus 4.5, ChatGPT 5.1, and Gemini 3 demonstrate significantly improved capabilities in understanding complex prompts [13] [14] — only when this foundation is exhausted and results don't meet requirements should more complex architectures be considered.
When RAG Makes Sense — and When It Doesn't

RAG (Retrieval Augmented Generation) combines the strengths of Large Language Models with external knowledge sources [15]. The core principle: LLMs are primarily text generators, and the knowledge acquired during training cannot be retrieved in a targeted and reliable way. In a RAG architecture, a data source is connected via a powerful search function. The LLM receives relevant information from this source and processes it for the given question — summarizing, contextualizing, and formulating the response [15].
RAG is valuable when current or company-specific knowledge is needed that is not contained in the model's training data [15]. Typical use cases include internal knowledge bases, document search, or FAQ systems. The biggest advantage: RAG significantly reduces hallucinations because the model accesses verified sources instead of unreliable "memory knowledge" [15].
RAG is less suited for creative tasks, when complex reasoning across multiple domains is required, or when the quality of source data is insufficient [15]. Keep in mind: a RAG solution is only as good as the underlying search function and the quality of the indexed documents.
Fine-Tuning: Opportunity or Cost Trap?
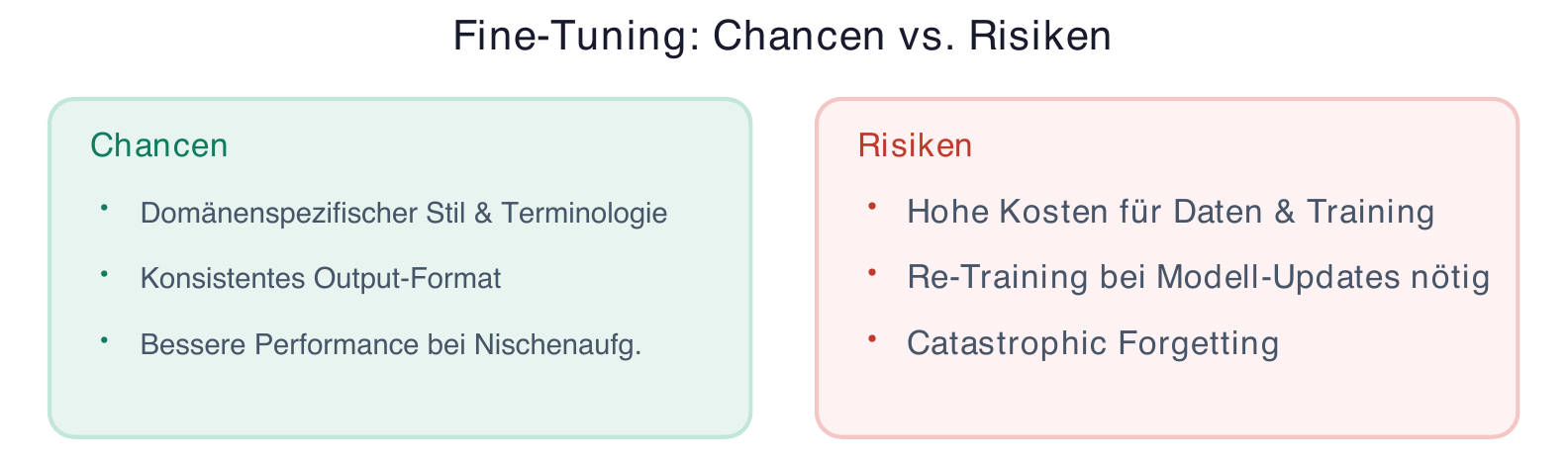
Fine-Tuning refers to the additional training of a pre-trained model on specific data [16]. The idea sounds tempting: a model tailored exactly to your own domain. The reality is more complex [17].
Fine-Tuning pays off primarily when a very specific style or specialized terminology is needed that cannot be achieved through prompts alone [18]. It is suited for tasks with a clearly defined, consistent output format and when sufficient high-quality training data is available [16].
The cost trap lurks in multiple places: initial data preparation is time-consuming, training itself consumes significant computing resources, and every base model update potentially requires re-fine-tuning [17]. There is also the risk of "Catastrophic Forgetting" — specialized training can cause the model to lose general capabilities [18].
Single Model vs. Multiple Specialized Models
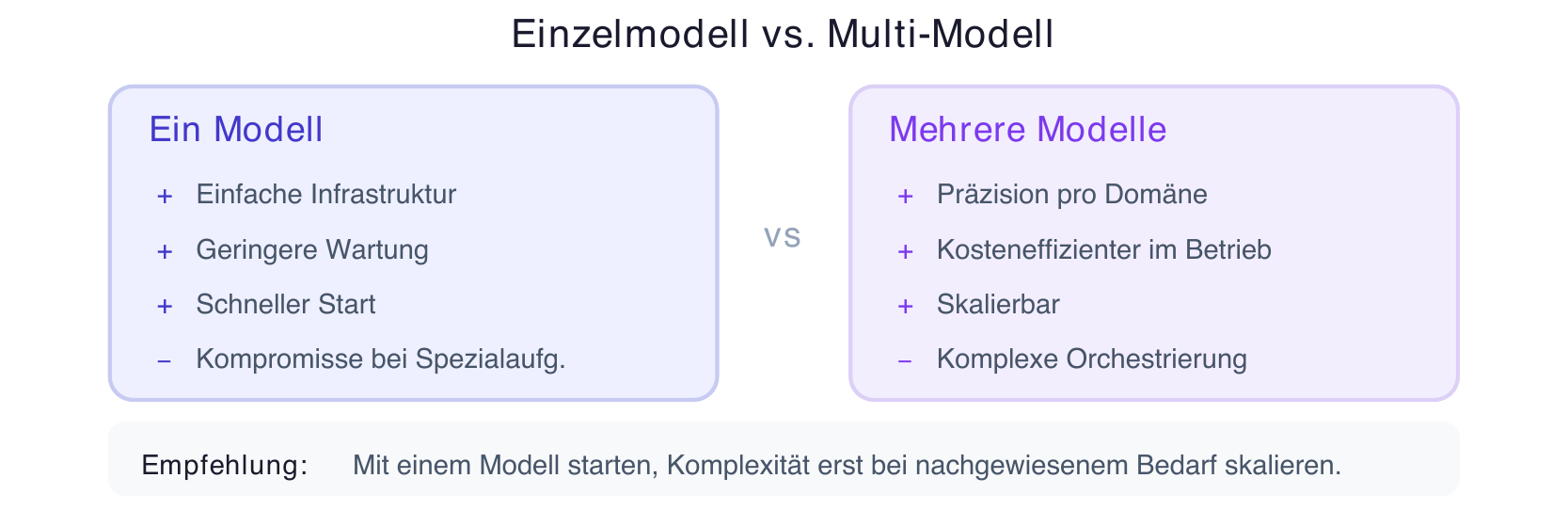
The question "One large model or several small ones?" cannot be answered universally [19]. A single powerful model simplifies infrastructure and maintenance. Multiple specialized models — an approach known as "Mixture of Experts" that is also used in Gemini 3 — can deliver more precise results in their respective domains and are often more cost-efficient to operate [9].
For practice: start with one model and scale complexity only when there is proven demand [12]. A multi-model architecture makes sense when there are clearly distinct task types where specialized models measurably outperform a generalist [20]. Interoperability between different AI systems is becoming increasingly important [21].
Models by Use Case
The choice of the right AI model and matching architecture is fundamentally determined by the specific use case [12]. The following sections analyze the most important application areas and provide concrete recommendations for managers and developers.
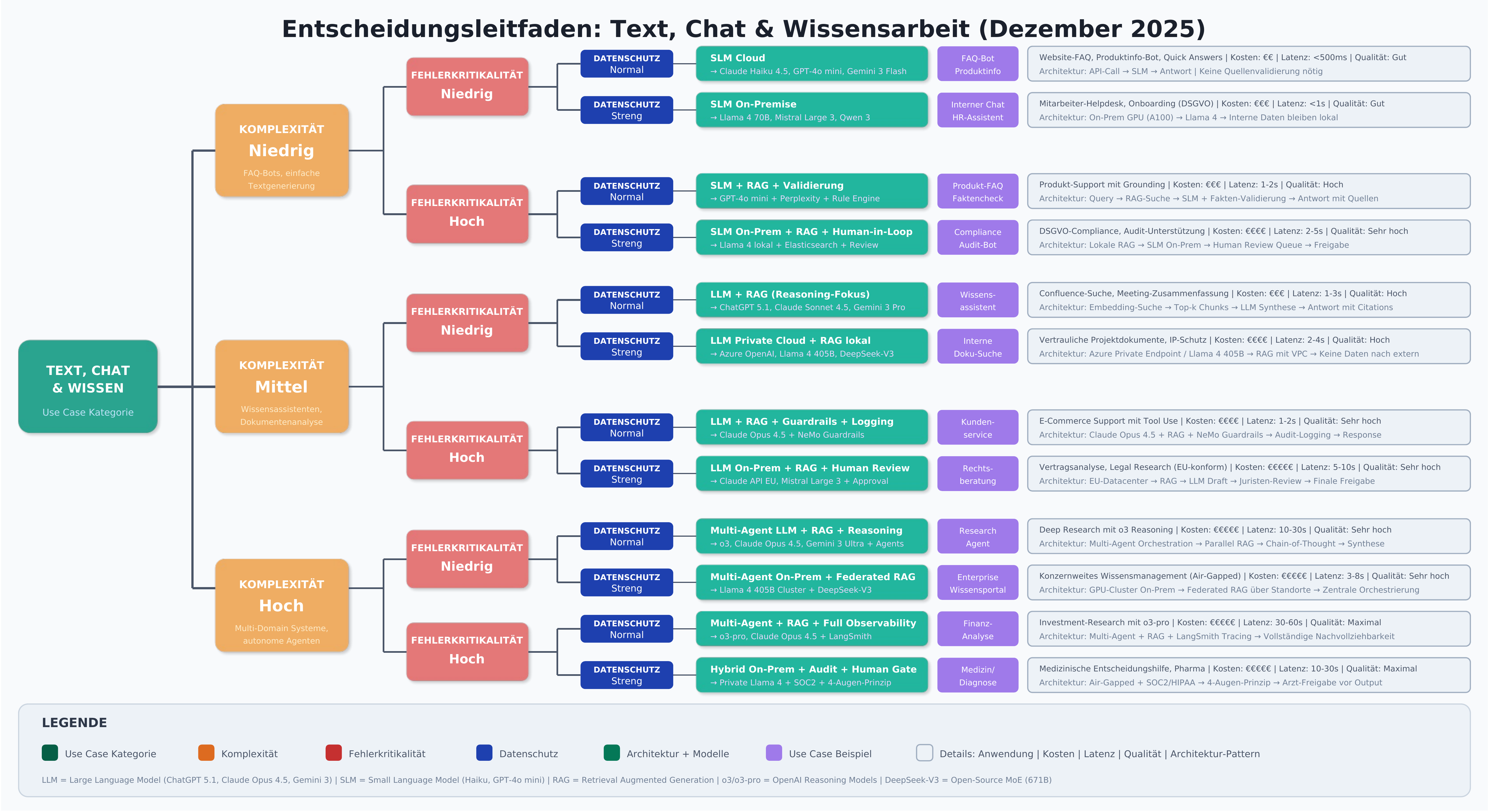
Text, Chat & Knowledge Work
Chatbots & Assistants
Problem: Companies need scalable communication channels that can handle customer inquiries around the clock without completely losing the quality of human interaction [12].
Model type: Large Language Models (LLMs) like ChatGPT 5.1, Claude Opus 4.5, or Gemini 3 Pro form the backbone of modern chatbot systems [13] [14]. For simpler, high-volume inquiries, smaller models (SLMs) like Mistral Large 3 or Llama 4 can be sufficient [19].
Recommended architecture: The optimal solution combines an LLM with RAG connected to the knowledge base [15]. This allows the chatbot to access current product information, pricing, and company-specific policies without having to "train them into" the model. For standard inquiries, a routing layer can delegate simpler questions to a more cost-efficient SLM while forwarding complex requests to the more powerful LLM [20].
Documents & Knowledge Search
Problem: Valuable company knowledge is scattered across thousands of documents, emails, and databases. Employees spend hours searching for relevant information [22].
Model type: Embedding models for semantic search are combined with LLMs for synthesizing and preparing the retrieved information [23].
Recommended architecture: RAG is the clear favorite here [15]. An embedding model vectorizes the documents and enables semantic similarity search. The most relevant text passages are provided to the LLM as context, which then formulates a coherent answer with source references. Claude Opus 4.5 supports context windows of up to 200,000 tokens, enabling the processing of extensive documents [14]. This architecture ensures the system always stays up to date — new documents are simply added to the index without retraining.
LLM + RAG vs. SLM: For knowledge work that demands nuances, connections, and precise source work, there is no way around LLMs with RAG [15]. SLMs can serve as a cost-efficient alternative when tasks are less complex or when summaries are needed rather than analytical processing [19]. The decisive factor is the complexity of requirements for text quality and contextual understanding.
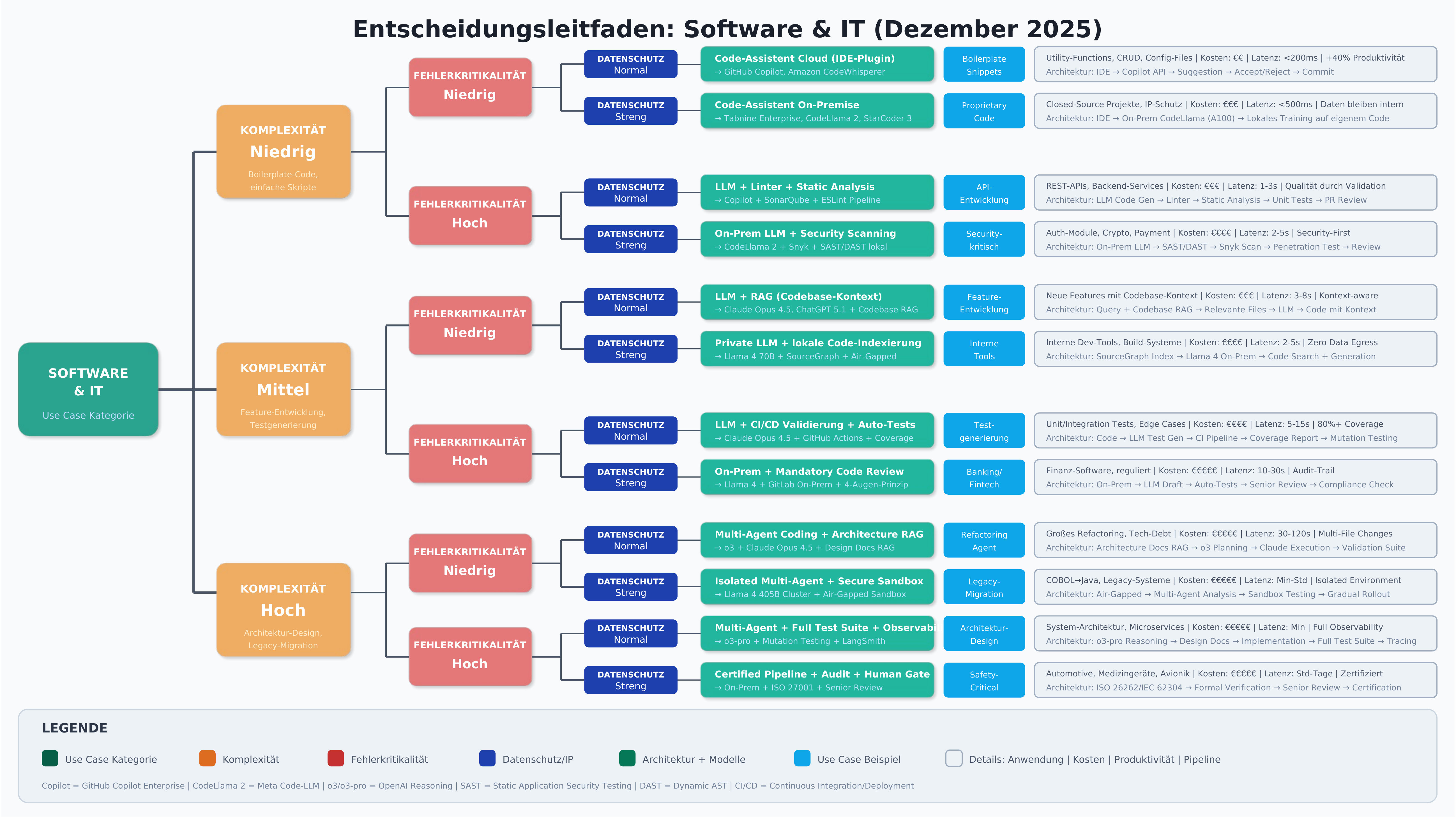
Software & IT
Code Generation
Problem: Developers spend significant time on repetitive programming tasks, boilerplate code, and implementing standard patterns [24].
Model type: Specialized code models like GitHub Copilot Enterprise, Claude Opus 4.5 with code focus, or open-source alternatives like CodeLlama 2 and StarCoder 3 are used [25]. These models were specifically trained on code repositories and understand programming conventions, syntax, and best practices [26]. According to a Bain study, generative AI boosts developer productivity by 20–40% [27].
Recommended architecture: Integration typically happens directly in the IDE [25]. The key is combining an LLM with validation logic: generated code must be checked by linters, static analysis, and ideally automated tests [26]. Blindly adopting AI-generated code creates technical debt and security risks. A workflow should be established where the AI makes suggestions that are then validated through automated and manual review [27].
Test Data & Test Cases
Problem: Creating realistic test data and comprehensive test cases is time-consuming and requires deep domain knowledge [26].
Model type: LLMs are excellent for generating test scenarios and edge cases, as patterns can be derived from the training data [24]. For generating large volumes of structured test data, specialized tools or smaller models with clearly defined schemas can be more efficient [25].
Recommended architecture: A two-stage approach has proven effective [27]: the LLM first generates test case descriptions and boundary conditions in natural language. These are then converted into executable tests through validation logic and checked for consistency. For test data, the combination of LLM-generated structure and rule-based data enrichment is recommended to ensure both realism and data quality [26].
Recommendation: Combining LLMs with validation logic is not optional in IT — it is mandatory [27]. AI-generated code and tests must always be verified through established quality assurance processes. Productivity gains come from accelerating the initial creation, not from shortcutting quality checks [26].
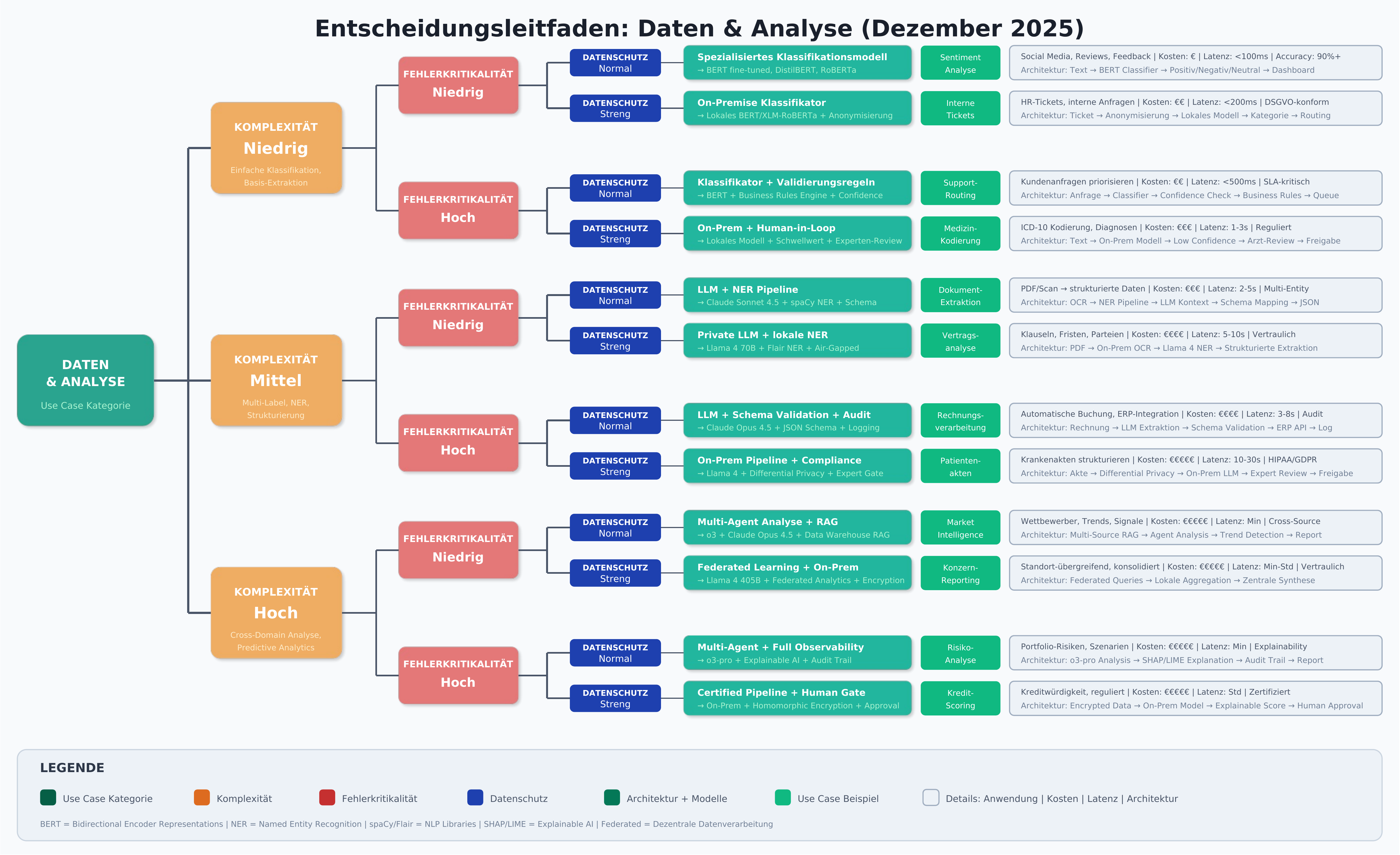
Data & Analysis
Classification
Problem: Companies need to categorize large volumes of data — whether support tickets, customer feedback, documents, or transactions [28].
Model type: For classification tasks, smaller specialized models are often the better choice compared to large LLMs [19]. BERT-based models or domain-specifically trained classifiers achieve higher accuracy at significantly lower inference costs for defined categories [29].
Recommended architecture: A fine-tuned classification model trained on the specific categories [18]. An LLM can support the initial category definition by identifying patterns in the data [30]. The specialized, more efficient model is then deployed for production classification. A continuous feedback loop is critical: misclassifications are collected and fed into regular retraining cycles [29].
Structuring Unstructured Data
Problem: Valuable information is trapped in free text, PDFs, emails, or handwritten notes and must be converted into structured formats [28].
Model type: Named Entity Recognition (NER) models are used for extracting defined entities, while LLMs handle more complex extraction tasks that require contextual understanding [31].
Recommended architecture: A pipeline approach is optimal here [30]: specialized models first extract known entity types (names, dates, amounts). The LLM handles the interpretation of ambiguous passages and mapping to the data schema [29]. Downstream validation rules check the plausibility of extracted data. This approach combines the efficiency of specialized models with the flexibility of LLMs [31].
Recommendation: In data and analysis, small highly specialized models often deliver better results than large generalists [30]. They are faster, cheaper to operate, and more precise for clearly defined tasks [29]. LLMs should be reserved for tasks that genuinely require language understanding and context interpretation [28].
Marketing & Content
Content Creation
Problem: Demand for high-quality content exceeds available resources in many companies [32]. Blog articles, social media posts, product descriptions, and newsletters must be produced at high frequency.
Model type: Large LLMs like ChatGPT 5.1, Claude Opus 4.5, or Gemini 3 Pro are the first choice here [13] [14]. Their strength lies in adapting different writing styles, implementing SEO requirements, and generating creative variations [32]. Specialized marketing AI tools like AdCreative.AI use fine-tuned models for specific advertising formats [33].
Recommended architecture: An LLM with carefully developed prompt templates for different content types is recommended [34]. The templates define tone, structure, target audience, and SEO parameters. A downstream review process by human editors ensures quality and brand conformity [35]. For recurring content formats, Fine-Tuning can reduce the prompting effort — the initial investment pays off here [17].
Personalization
Problem: Customers expect individually tailored communication. Generic mass messaging is losing effectiveness [35].
Model type: A combination of recommendation systems (often based on classical ML) and LLMs for linguistic personalization is used [36]. LLMs can interpret customer profiles and adapt the messaging accordingly [34].
Recommended architecture: A hybrid system is recommended [35]: traditional recommendation algorithms identify relevant products or content based on user behavior. The LLM then formulates personalized messaging that contextualizes these recommendations and links them to the individual customer profile [36]. RAG can integrate customer history and preferences as context here [15].
Purchase Recommendations (E-Commerce)
Problem: E-commerce platforms must select the most relevant products from thousands for each individual customer and present them convincingly [36].
Model type: For the recommendation logic itself, specialized recommendation models (Collaborative Filtering, Content-Based Filtering) are often more efficient than LLMs [34]. LLMs are deployed for explaining and presenting the recommendations [35].
Recommended architecture: A three-stage system is recommended [36]: first, rule-based systems filter by hard criteria (availability, price, category). Then ML-based recommendation models rank by relevance. Finally, the LLM generates convincing, personalized product descriptions and purchase arguments [32]. For high-volume scenarios, these LLM-generated texts can be pre-computed and cached.
Marketing & Content recommendation: In marketing and content, large LLMs with clearly structured prompts are the most effective solution [32]. Result quality is strongly influenced by prompt precision — invest time in developing and testing prompt templates [34]. For repetitive, high-volume tasks, Fine-Tuning can improve consistency and reduce prompting effort [17].
AI Models by Use Case — Overview
| Use Case | Firma | Modell | Vorteile | Nachteile |
|---|---|---|---|---|
| Bildgen. | OpenAI | DALL-E 4 | Höchste Bildqualität, exzellente Textumsetzung, ChatGPT 5.1-Integration | Eingeschr. Stilkontrolle, Premium-Pricing |
| OpenAI | DALL-E 3 | Bewährte Stabilität, günstigere API-Kosten | Qualität unter DALL-E 4 | |
| Midjourney | Midjourney v7 | Exzell. künstlerische Qualität, Realismus-Modi, starke Community | Web-Interface nötig, steile Lernkurve | |
| Stability AI | Stable Diff. 4 | Open Source, lokale Installation, volle Kontrolle | Hoher techn. Aufwand, Hardware-Anf. | |
| Stability AI | Stable Diff. XL | Bewährt, breite Community, flexible Lizenzen | Qualität unter SD4, kompl. Setup | |
| Adobe | Firefly 3 | Rechtl. abgesichert, Creative-Cloud-Integration | Eingeschr. Freiheit, Abo nötig | |
| Entsch.-hilfe | OpenAI | ChatGPT 5.1 | Exzell. Reasoning, Weltwissen, multimodal, schnelle Inferenz | Hohe API-Kosten, US-Datenhaltung |
| OpenAI | GPT-4 Turbo | Großes Kontextfenster, zuverlässig, günstiger als 5.1 | Langsamer, geringer. Reasoning-Qual. | |
| Anthropic | Claude Opus 4.5 | Beste Analyse, 200k Token Kontext, nuanciertes Denken | Premium-Pricing, langsamere Antw. | |
| Anthropic | Claude Sonnet 4.5 | Ausgewog. Preis-Leistung, schnell | Geringere Tiefe als Opus 4.5 | |
| Gemini 3 Ultra | Beste multimodale Fähigk., Echtzeit-Daten, Workspace-Int. | Datenschutzbedenken, reg. Einschr. | ||
| Gemini 3 Pro | Gutes Preis-Leistungs-Verh., solide Performance | Variable Qual. bei kompl. Aufgaben | ||
| Meta | Llama 4 70B | Open Source, selbst hostbar, keine API-Kosten | Eigene Infrastruktur nötig | |
| Testgen. | GitHub/MS | Copilot Enterprise | Nahtlose IDE-Integration, kontextbewusst, Team-Features | Enterprise-Pricing, Datenschutzfr. |
| GitHub/MS | Copilot Individual | Günstig, breite IDE-Unterstützung | Weniger Features als Enterprise | |
| Anthropic | Claude Opus 4.5 | Präzise Edge-Cases, ausführliche Testdokumentation | Kein IDE-Plugin, manuell. Workflow | |
| OpenAI | ChatGPT 5.1 | Breites Sprachspektrum, gute Testabdeckung | Generalist, nicht code-spezialisiert | |
| Amazon | CodeWhisperer Pro | AWS-Integration, Sicherheitsscans, kostenlose Tier | Primär AWS-fokussiert | |
| Tabnine | Tabnine Enterprise | On-Premises, DSGVO-konform, Code-Privacy | Geringere Kreativität als Copilot | |
| Videogen. | OpenAI | Sora 2.0 | Filmreife Qualität, Physikverständnis, bis 60 Sek. | Hohe Kosten, eingeschr. Zugang |
| OpenAI | Sora 1.0 | Bewährte Stabilität, breiter verfügbar | Kürzere Clips, weniger Kontrolle | |
| Runway | Gen-4 | Professionelle Features, Bewegungssteuerung, Filmproduktion | Hohe Kosten, Lernkurve | |
| Runway | Gen-3 Alpha | Gutes Preis-Leistungs-Verh., breite Funktionspalette | Qualität unter Gen-4 | |
| Pika Labs | Pika 2.0 | Intuitive Bedienung, schnell, Bild-zu-Video-Funktion | Kurze Clips, eingeschr. Kontrolle | |
| Stability AI | Stable Video 2 | Open Source, lokale Nutzung, volle Kontrolle | Kurze Videos, hohe Hardware-Anf. | |
| Veo 2 | Hohe Auflösung, Google-Ökosystem-Integration | Eingeschr. Zugang, Google-Lock-in | ||
| Allrounder | OpenAI | ChatGPT 5.1 | Beste Gesamtperf., multimodal, schnell, größtes Plugin-Öko. | Premium-Preis, US-Daten, Inkonsist. |
| OpenAI | GPT-4 Turbo | Großes Kontextfenster, zuverlässig, günstiger | Langsamer, geringere Qual. als 5.1 | |
| OpenAI | GPT-4o | Sehr schnell, gutes Preis-Leistungs-Verhältnis | Qualität unter ChatGPT 5.1 | |
| Anthropic | Claude Opus 4.5 | Bestes Reasoning, 200k Kontext, sicherheitsorientiert | Premium-Pricing, kein Bildgen. | |
| Anthropic | Claude Sonnet 4.5 | Ausgewog. Preis-Leistung, schnell | Geringere Analysetiefe als Opus | |
| Gemini 3 Ultra | 1M+ Token Kontext, multimodal, Echtzeit-Websuche | Datenschutzbedenken, variable Qual. | ||
| Meta | Llama 4 405B | Größtes Open-Source-Modell, keine Lizenzkosten | Enorme Hardware-Anf., kein Support | |
| Mistral AI | Mistral Large 3 | Europ. Anbieter, DSGVO-freundlich, gut. Preis-Leistung | Kleineres Öko., weniger multimodal |
Decision Guide
The following decision trees provide visual orientation for choosing the right AI model and the appropriate architecture.

Common Mistakes and Best Practices
Implementing AI systems is complex and multi-layered. Despite growing experience, many companies stumble over the same obstacles. Analysis of the literature shows that these mistakes are usually not technical but organizational and strategic in nature.
Common Mistakes
Lacking Strategic Planning and Unrealistic Expectations
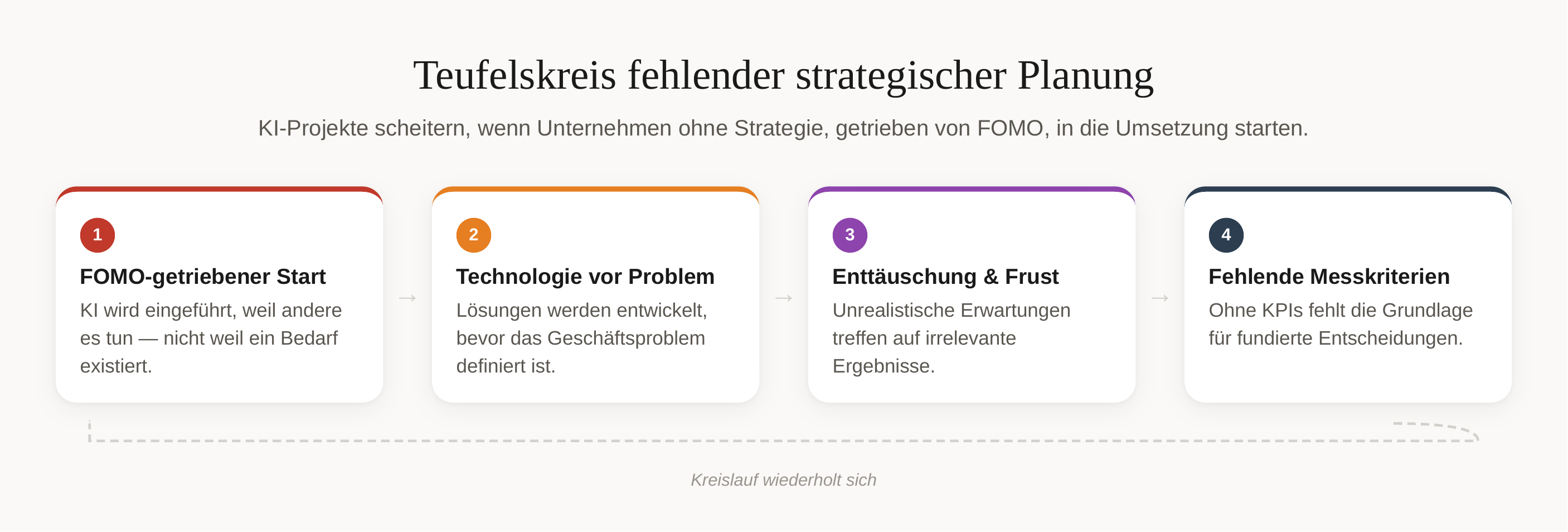
The most severe mistake begins before the actual implementation: many companies launch AI projects without a clear strategy. Organizations often implement AI solutions out of FOMO (Fear of Missing Out) without defining concrete use cases [47]. AI is not a silver bullet, and unrealistic expectations inevitably lead to disappointment [50].
The technology-driven approach is particularly problematic: many projects start with the technology instead of the problem [51]. This leads to solutions that are technically impressive but business-irrelevant. Lack of goal definition is identified as one of the three typical problems in AI implementation [48]. Without clear KPIs and measurable success criteria, the foundation for informed decisions throughout the entire project is missing.
Insufficient Data Quality and Preparation
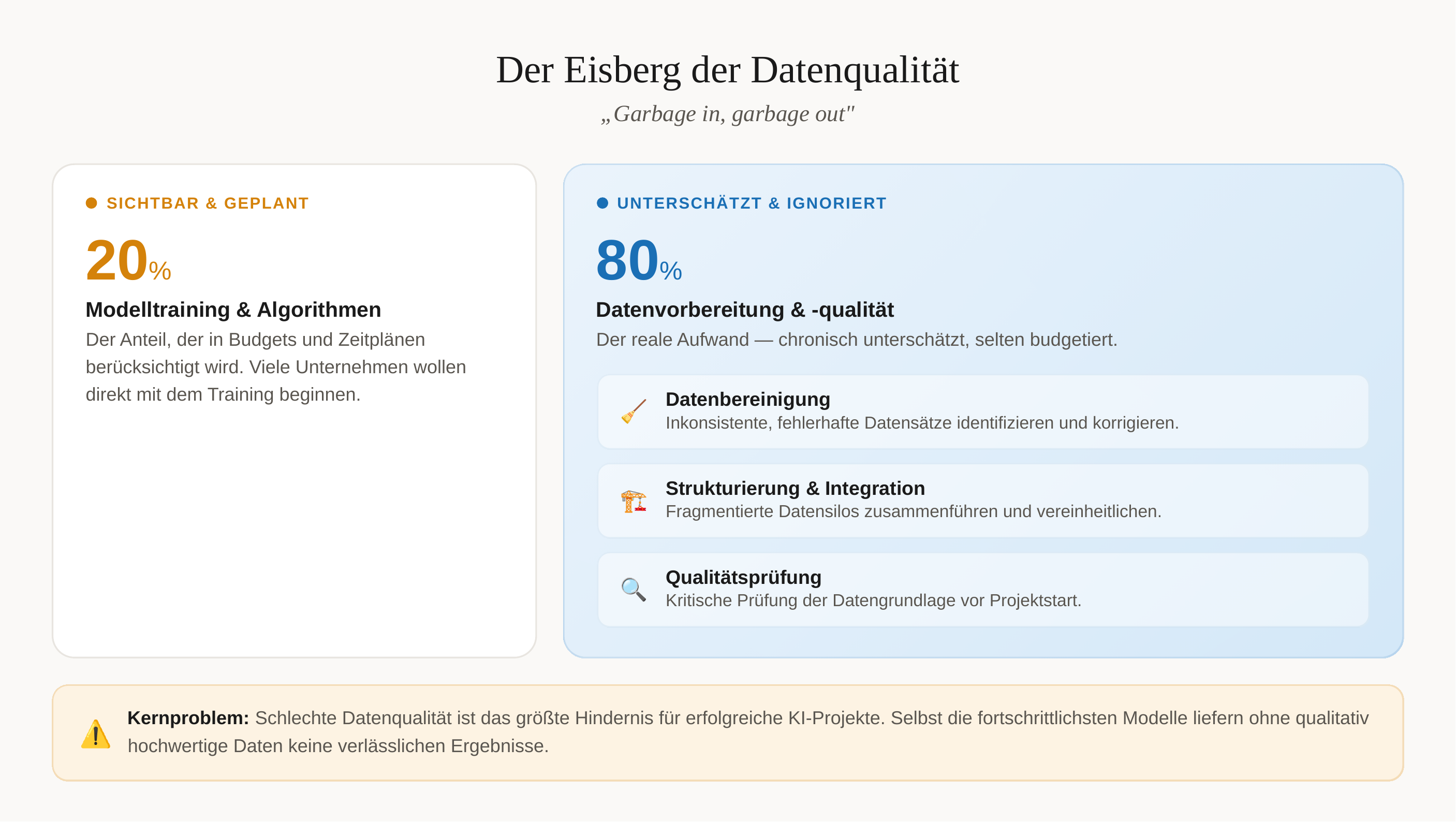
"Garbage in, garbage out" — this principle applies nowhere as strongly as in AI systems. Poor data quality is the biggest obstacle to successful AI projects [41]. Many organizations dramatically underestimate this challenge. SMEs in particular underestimate the importance of data preparation and want to jump straight to training without critically examining the data foundation [46].
The consequences are far-reaching: without structured, high-quality data, even the most advanced AI models cannot deliver reliable results. A frequently overlooked fact: 80% of work in AI projects goes into data preparation — an effort that is often underestimated or even ignored in initial planning and budgeting [48].
Insufficient Employee Involvement

The "human factor" is frequently neglected in the excitement about technology — a fatal mistake. AI projects often fail not because of technical limitations but because of lacking employee acceptance [51]. Fear of job loss and insufficient training lead to active or passive resistance that can doom even technically successful implementations [47].
The opposite approach is advisable: employees should be involved from the start and won over as "AI champions" who drive the project internally [52]. This early participation not only creates acceptance but also taps into the existing domain knowledge that is indispensable for successful implementation.
Best Practices for Successful AI Implementation
Problem-Centered Approach Instead of Technology Push
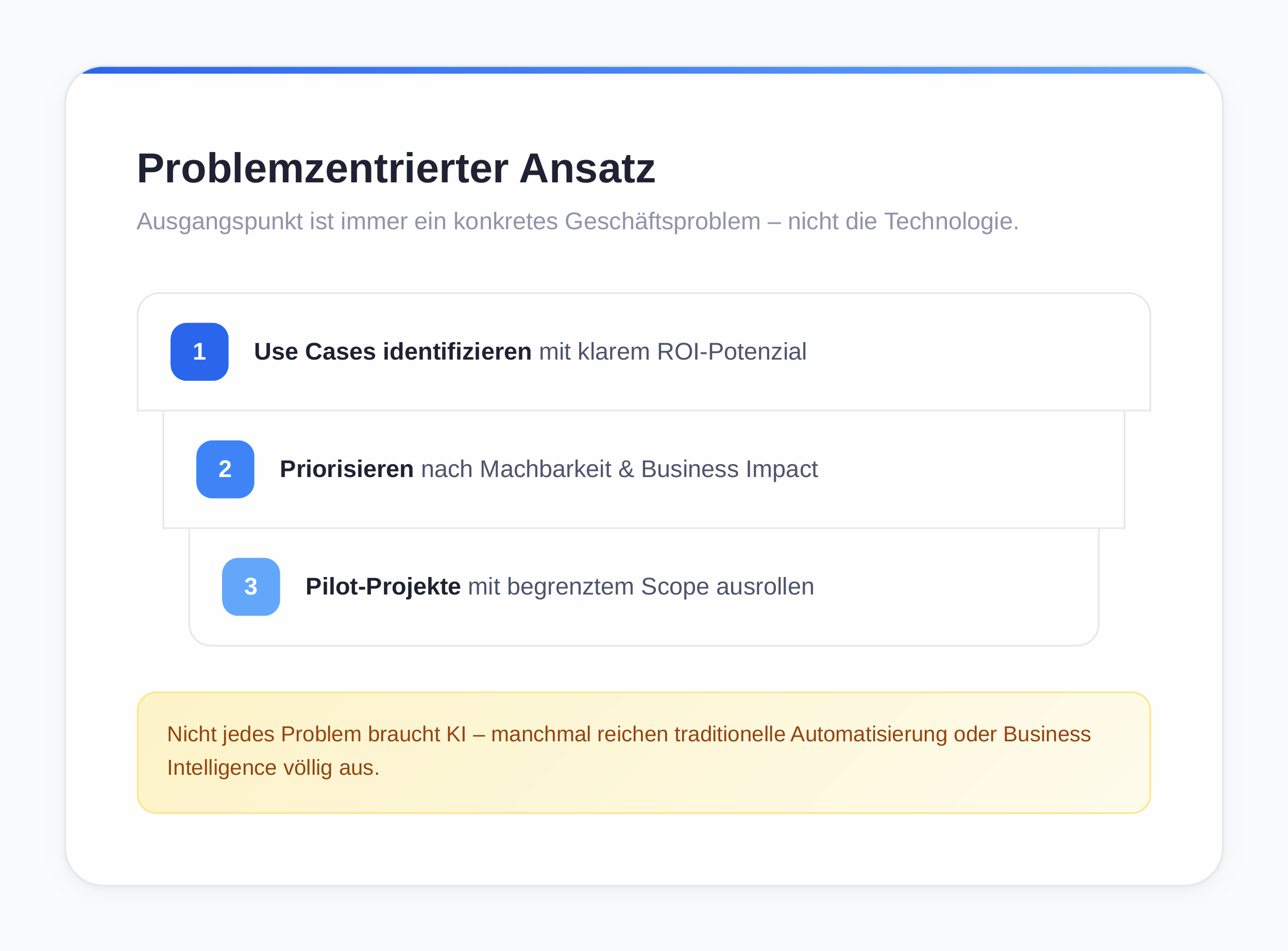
The starting point of every successful AI project should be a concrete business problem, not the technology itself. A systematic approach is recommended: start with concrete business problems, identify measurable KPIs, and only then select the appropriate AI solution [52]. Not every problem requires AI — sometimes traditional automation or business intelligence is sufficient [40].
The following concrete steps are recommended:
- Identify use cases with clear ROI potential (ROI potential describes the maximum return on an investment relative to the resources deployed)
- Prioritize selected use cases by feasibility and business impact
- Roll out pilot projects with limited scope
This pragmatic approach prevents wasted resources and creates early wins that are critical for broader adoption [50].
Systematic Model Selection by Use Case
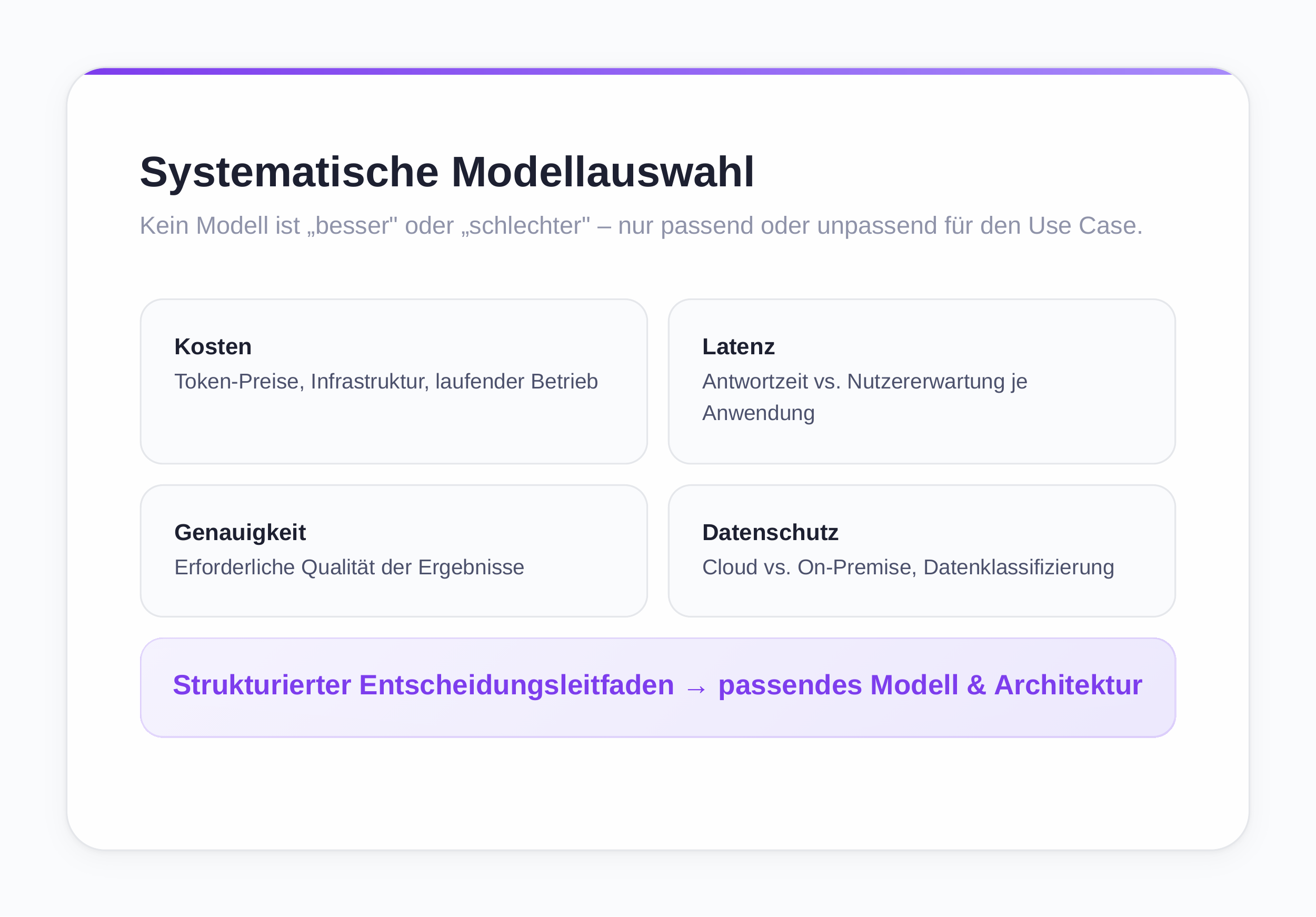
Choosing the right AI model is not a question of "better" or "worse" but of "suitable" or "unsuitable" for the specific use case. A structured decision guide for model selection and the discussion of architecture decisions considering the various dimensions have already been presented in the previous chapters [43].
Change Management and Employee Training

Technical implementation is only half the battle — no AI works without the people. The importance of cultural change is emphasized, with a three-pronged approach [49]:
- Transparent communication: take fears seriously while highlighting opportunities
- Hands-on training instead of theoretical workshops to enable practical experience
- Demonstrate quick wins and make early successes visible to build trust
Iterative Implementation with Feedback Loops
Instead of a "Big Bang" approach, an agile, iterative methodology is recommended [40]: the MVP phase (Minimal Viable Product) should deliver a minimal functional product in 4–8 weeks. This is then tested in a pilot phase with real users to collect feedback and measure metrics. Iterative improvement follows based on this user data. Only after proven functionality comes the gradual scaling to additional areas or user groups.
"The best AI tools are the ones that actually get used" [45]. Simple solutions well integrated into existing processes beat complex systems that nobody understands or can operate. The focus should be on usability and practical value, not technical perfection.
Legal and Ethical Framework
AI operates in a complex legal and ethical environment that must be considered from the start. Legal pitfalls are a real concern [43]: GDPR (DSGVO) compliance must be planned from the beginning, not retrofitted. The transparency and traceability of AI decisions must be ensured, especially for decisions that affect people. Regular bias monitoring is required to detect and correct discriminatory patterns early.
Continuous Monitoring and Optimization
AI systems are not static software products — they require continuous maintenance. The necessity of operational excellence is emphasized [49]: performance monitoring should automatically track accuracy and latency. Drift detection identifies when input data changes enough to degrade model performance. A clear retraining strategy plans updates based on new data and evolving requirements.
Outlook
The future of AI implementation lies not in finding the one perfect model but in the intelligent combination of different systems. The paradigm shift from the "One-Model-Fits-All" approach toward orchestrated, modular AI systems is already clearly emerging and promises higher efficiency, better results, and greater flexibility.
From Monolith to Orchestration
The idea that a single AI model could cover all of a company's requirements is increasingly proving to be an illusion [53]. Instead, the realization is gaining ground that different tasks require different models — and that true innovation lies in their intelligent combination. Skillful orchestration can harness the strengths of different models while compensating for their respective weaknesses [54].
The trend is moving away from monolithic single solutions toward flexible, modular architectures. Generative AI is becoming increasingly multimodal [55] — processing and combining different data types like text, image, audio, and video seamlessly.
Compound AI Systems: AI as a System, Not a Model
The concept of Compound AI Systems marks a fundamental shift in perspective [56]. Instead of a single model, multiple specialized components are connected into an integrated system. Each component handles specific tasks it is optimized for. An example: a customer service system could use a fast SLM for simple inquiries, activate a powerful LLM for complex problem-solving, and deploy a specialized classification model for sentiment analysis — all orchestrated through intelligent routing logic.
Ensemble methods in machine learning have shown for years how combining multiple models leads to superior performance [57]. In Ensemble Modeling, multiple models are trained and their predictions combined to achieve more robust and accurate results [58]. These principles also transfer to large language models. Different models can process the same task in parallel, and their outputs are intelligently merged [59]. This not only increases accuracy but also reduces hallucinations.
Agentic AI and Multi-Agent Systems
A particularly promising approach is multi-agent systems, where specialized AI agents collaborate autonomously [60]. Each agent has specific capabilities and can communicate and cooperate with other agents. A research agent could collect information, an analysis agent evaluate it, a planning agent develop strategies, and an execution agent carry out concrete actions — all orchestrated by a higher-level system.
Practical Advantages of Combination
Combining multiple AI models offers concrete business advantages [54]: higher efficiency through specialization, cost optimization through intelligent routing, better fault tolerance through redundancy, and flexibility in model selection.
Combining different models also enables better compliance and governance [55]. Sensitive data can be processed with local SLMs while less critical tasks are delegated to cloud-based LLMs. These hybrid architectures unite the best of both worlds: data privacy and control on one side, performance and up-to-date capabilities on the other.
From Theory to Practice
Practical implementation requires new competencies, however [56]. Instead of training individual models, companies must learn to orchestrate complex AI systems. This includes routing logic that directs requests to the appropriate model, fallback mechanisms for failure scenarios, monitoring across multiple models, and continuous optimization of collaboration between components.
Call-to-Action
The future of AI lies not in ever-larger individual models but in intelligent systems of specialized components. This paradigm shift requires a change in thinking:
- View AI as an architecture, not a product
- Don't search for the best model — orchestrate the best combination
- Don't build monolithically — compose modularly
What matters is that the choice should primarily depend on the specific use case and existing integrations, not on marketing promises. The best model is useless if it can't be integrated into the existing infrastructure or if costs outweigh the benefits. Pragmatism beats perfectionism.
Companies that make this transition early gain decisive advantages: they are more flexible in model selection, more efficient in resource allocation, more robust against failures, and better prepared for future developments. The question is no longer "Which model?" — but "How do we combine models into a system that optimally meets our specific requirements?" [53] [54].
Sources
- [1] Wissence (2024): "Which AI for What: AI Models Compared." https://www.wissence.at/post/ki-modelle-im-vergleich-use-cases
- [2] IBM (2024): "What Is an AI Model?" https://www.ibm.com/de-de/think/topics/ai-model
- [3] IBM (2024): "What Are Large Language Models (LLMs)?" https://www.ibm.com/de-de/think/topics/large-language-models
- [4] Databricks (2024): "Machine Learning Models." https://www.databricks.com/de/glossary/machine-learning-models
- [5] Own illustration: comparison table of decision factors for AI models.
- [6] ArXiv (2025): "Small Language Models are the Future of Agentic AI." https://arxiv.org/pdf/2506.02153
- [7] Hugging Face (2024): "Small Language Models (SLM): A Comprehensive Overview." https://huggingface.co/blog/jjokah/small-language-model
- [8] Red Hat (2024): "SLMs vs LLMs: What are small language models?" https://www.redhat.com/en/topics/ai/llm-vs-slm
- [9] Harvard Business Review (2025): "The Case for Using Small Language Models." https://hbr.org/2025/09/the-case-for-using-small-language-models
- [10] Intel (2024): "Xeon for Small Language Models." https://www.intel.de/content/www/de/de/goal/xeon-for-small-language-models.html
- [11] Gartner (2024): "Hype Cycle for Artificial Intelligence." https://www.gartner.com/en/articles/hype-cycle-for-artificial-intelligence
- [12] Codecentric (2024): "How to Find the Right Generative AI Use Cases?" https://www.codecentric.de/wissens-hub/blog/wie-finde-ich-die-richtigen-generative-ki-use-cases-5-learnings-aus-der-praxis
- [13] The Prompt Buddy (2025): "Best AI Models December 2025." https://www.thepromptbuddy.com/prompts/best-ai-models-december-2025-top-language-models-you-can-use-today
- [14] LitsLink (2024): "3 Most Advanced AI Systems Overview." https://litslink.com/blog/3-most-advanced-ai-systems-overview
- [15] Fraunhofer IESE (2024): "Retrieval Augmented Generation (RAG)." https://www.iese.fraunhofer.de/blog/retrieval-augmented-generation-rag/
- [16] ContentPipe (2024): "Fine-Tuning — Glossary." https://contentpipe.io/glossar/fine-tuning/
- [17] Computerwoche (2024): "Fine-Tuning Is Expensive — But Often Worth It." https://www.computerwoche.de/article/2828262/finetuning-ist-teuer-aber-oft-lohnt-es-sich.html
- [18] DataScientest (2024): "AI Fine-Tuning." https://datascientest.com/de/ai-fine-tuning-alles-ueber-diese-spezialisierungstechnik-von-kis
- [19] Novidata (2024): "AI Systems, AI Models and AI Tools." https://novidata.de/ki/ki-systeme-ki-modell-und-ki-tools/
- [20] KI-Beratung (2024): "Mixture of Experts." https://www.kiberatung.de/ki-glossar/mixture-of-experts-expertengemisch
- [21] Xpert.Digital (2024): "AI Interoperability." https://xpert.digital/ki-interoperabilitaet/
- [22] GWriters (2024): "Writing Academic Papers with AI." https://gwriters.de/blog/wissenschaftliche-arbeit-mit-ki-schreiben
- [23] University of Duisburg-Essen (2024): "AI Tools." https://www.uni-due.de/ub/ki-tools.php
- [24] IBM (2024): "AI in Software Development." https://www.ibm.com/de-de/think/topics/ai-in-software-development
- [25] Entwickler.de (2024): "Top 10 AI Tools for Software Development." https://entwickler.de/machine-learning/top-10-ki-tools-software-entwicklung
- [26] HCO (2024): "The Best AI Tools for Developers." https://www.hco.de/blog/die-besten-ki-tools-fur-entwickler-effizienter-programmieren-mit-chatgpt-claude-copilot-co
- [27] Bain & Company (2025): "From Pilots to Payoff: Generative AI in Software Development." https://www.bain.com/insights/from-pilots-to-payoff-generative-ai-in-software-development-technology-report-2025/
- [28] IONOS (2024): "AI Data Analysis." https://www.ionos.de/digitalguide/online-marketing/web-analyse/ai-data-analysis/
- [29] NetSuite (2024): "AI in Data Analysis." https://www.netsuite.com/portal/resource/articles/erp/ai-in-data-analysis.shtml
- [30] Juma.AI (2024): "Using AI for Data Analysis." https://juma.ai/blog/using-ai-for-data-analysis-6-use-cases-statistics-examples-and-tools
- [31] Numerous.AI (2024): "Free AI Tools for Data Analysis." https://numerous.ai/blog/free-ai-tools-for-data-analysis
- [32] Pipedrive (2024): "AI Marketing." https://www.pipedrive.com/de/blog/ai-marketing
- [33] AdCreative.AI (2024): "Top 10 AI-Powered Marketing Tools." https://de.adcreative.ai/post/top-10-ai-powered-marketing-tools-that-can-increase-return-on-ad-spend
- [34] Marketer Milk (2024): "AI Marketing Tools." https://www.marketermilk.com/blog/ai-marketing-tools
- [35] Salesforce (2024): "AI in Marketing." https://www.salesforce.com/de/blog/ai-im-marketing/
- [36] All About AI (2024): "AI Statistics and AI Models." https://www.allaboutai.com/de-de/ressourcen/ki-statistiken/ki-modelle/
- [37] Air Street Press (2025): "The State of AI 2025." https://press.airstreet.com/p/the-state-of-ai-2025-dec
- [38] Karrierewelt Golem (2025): "AI Chatbots Compared 2025." https://karrierewelt.golem.de/blogs/karriere-ratgeber/ki-chatbots-im-vergleich-2025
- [39] Getronics (2024): "Types of AI: Which is the Right Fit for Your Business?" https://www.getronics.com/de/types-of-ai-which-is-the-right-fit-for-your-business/
- [40] ABC Finance (2024): "Best Practices: AI Projects in Mid-Sized Companies." https://www.abcfinance.de/blog/artikel/best-practices-ki-projekte-im-mittelstand/
- [41] AISphere Media (2024): "5 Mistakes in AI Adoption." https://www.aispheremedia.de/5-fehler-bei-der-ki-einfuehrung-die-du-garantiert-vermeiden-kannst/
- [42] BR (2024): "ChatGPT & Co: Which AI Is Good for What?" https://www.br.de/nachrichten/netzwelt/chatgpt-and-co-welche-ki-taugt-fuer-was,UYXumzO
- [43] Computerwoche (2024): "Best Practice for Successful AI Deployment." https://www.computerwoche.de/article/2780807/best-practice-fuer-den-erfolgreichen-ki-einsatz.html
- [44] Datasolut (2024): "Application Areas of Artificial Intelligence." https://datasolut.com/anwendungsgebiete-von-kuenstlicher-intelligenz/
- [45] Ingenieur.de (2024): "These AI Tools Are Truly Worth It." https://www.ingenieur.de/technik/fachbereiche/kuenstliche-intelligenz/diese-ki-tools-lohnen-sich-wirklich/
- [46] IT-P (2024): "The 5 Most Common Mistakes in AI Projects for SMEs." https://www.it-p.de/blog/5-haeufigsten-fehler-ki-projekte-kmu/
- [47] Kreutzpointner (2024): "Common Mistakes in AI Usage." https://kreutzpointner.de/haeufige-fehler-bei-der-ki-nutzung-und-wie-man-sie-vermeidet/
- [48] Mindsquare (2024): "3 Typical Problems in AI Implementation." https://mindsquare.de/allgemein/3-typische-probleme-bei-der-ki-implementierung/
- [49] Mindsquare (2024): "Artificial Intelligence — Know-how." https://mindsquare.de/knowhow/kuenstliche-intelligenz/
- [50] Plattform Lernende Systeme (2024): "AI in Practice." https://www.plattform-lernende-systeme.de/ki-praxis.html
- [51] TAW (2024): "AI Implementation Mistakes." https://www.taw.de/blog/implementierungsfehler-von-ki
- [52] Zukunftszentren (2024): "Best Practices: Introducing AI Applications in SMEs." https://zukunftszentren.de/wissenspool/best-practices-einfuehrung-von-ki-anwendungen-in-kmu/
- [53] Marketing Institut (2024): "AI Models: Overview and Use Case Scenarios." https://www.marketinginstitut.biz/blog/ki-modelle/
- [54] SciSimple (2025): "Combining AI Models for Greater Efficiency." https://scisimple.com/de/articles/2025-06-04-ki-modelle-kombinieren-fuer-mehr-effizienz–ak5gw2n
- [55] Digitalzentrum Spreeland (2024): "Generative AI: Multimodality and Comparison Criteria." https://www.digitalzentrum-spreeland.de/Kuenstliche-Intelligenz/KI-Blog/Generative-KI-Multimodalitaet-und-Vergleichskriterien-von-KI-Modellen.html
- [56] IBM (2024): "Compound AI Systems." https://www.ibm.com/de-de/think/topics/compound-ai-systems
- [57] Dida (2024): "Ensembles in Machine Learning." https://dida.do/de/blog/ensembles-in-machine-learning
- [58] EODA (2024): "E for Ensemble Modeling." https://www.eoda.de/blog/e-wie-ensemble-modeling/
- [59] Ultralytics (2024): "Ensemble Methods." https://www.ultralytics.com/de/glossary/ensemble
- [60] Fraunhofer IESE (2024): "Agentic AI: Multi-Agent Systems." https://www.iese.fraunhofer.de/blog/agentic-ai-multi-agenten-systeme/
Glossary
| Begriff | Erklärung |
|---|---|
| Agentic AI | KI-Systeme, die eigenständig Aufgaben planen, ausführen und Entscheidungen treffen können – ähnlich einem Mitarbeiter, der einen Auftrag selbstständig in Teilschritte zerlegt und abarbeitet. |
| Algorithmus | Eine Schritt-für-Schritt-Anleitung, nach der ein Computer eine Aufgabe löst. Vergleichbar mit einem Kochrezept. |
| API | Technische Schnittstelle, über die verschiedene Software-Systeme miteinander kommunizieren können. API-Kosten entstehen pro Anfrage. |
| BERT | Ein von Google entwickeltes KI-Sprachmodell, das besonders gut die Bedeutung von Wörtern im Zusammenhang versteht. Häufig für Klassifikationsaufgaben eingesetzt. |
| Bias | Systematische Verzerrung in KI-Ergebnissen durch einseitige oder unausgewogene Trainingsdaten. |
| Catastrophic Forgetting | Problem beim Fine-Tuning: Das Modell wird besser im Spezialgebiet, verliert aber allgemeines Wissen. |
| Chatbot | Computerprogramm, das menschliche Gespräche simuliert. Moderne Chatbots nutzen LLMs für natürlich klingende Antworten. |
| Cloud-basiert | Software, die über das Internet von einem externen Anbieter bereitgestellt wird. |
| Collaborative Filtering | Empfehlungsmethode: „Kunden, die A kauften, kauften auch B." |
| Compliance | Einhaltung gesetzlicher Vorschriften, interner Regeln und Standards (z. B. DSGVO). |
| Compound AI Systems | Architekturansatz, bei dem mehrere spezialisierte KI-Komponenten zu einem Gesamtsystem verbunden werden. |
| Content-Based Filtering | Empfehlungsmethode basierend auf Produkteigenschaften. |
| CPU / GPU | CPU: Hauptprozessor. GPU: Grafikprozessor, ideal für KI-Training durch parallele Berechnungen. |
| Deep Learning | Spezielle Form des ML mit besonders vielen Schichten neuronaler Netze. |
| Deployment | Bereitstellung und Inbetriebnahme eines KI-Modells in der produktiven Umgebung. |
| Drift-Detection | Automatische Erkennung, wenn sich Eingabedaten so verändern, dass die Modellleistung nachlässt. |
| DSGVO | Europäische Verordnung zum Schutz personenbezogener Daten. |
| Edge-Gerät | Gerät, das Daten direkt vor Ort verarbeitet (z. B. Smartphones, IoT-Sensoren). |
| Embedding-Modell | KI-Modell, das Texte in mathematische Zahlenvektoren umwandelt für Ähnlichkeitssuchen. |
| Ensemble-Methoden | Kombination mehrerer KI-Modelle für robustere Ergebnisse. |
| Fallback-Mechanismus | Rückfallsystem, das einspringt, wenn das primäre System ausfällt. |
| Feedback-Loop | Systematischer Kreislauf zur kontinuierlichen Verbesserung eines KI-Systems. |
| Few-Shot Learning | Fähigkeit, Aufgaben mit nur wenigen Beispielen zu lösen. |
| Fine-Tuning | Nachtrainieren eines vortrainierten KI-Modells auf eigene, spezifische Daten. |
| FOMO | Fear of Missing Out – Angst, etwas zu verpassen. Im KI-Kontext: Projekte ohne eigene Strategie. |
| Governance | Regelwerk und Prozesse zur Steuerung und Kontrolle von KI-Systemen. |
| Halluzination | KI generiert überzeugend klingende, aber faktisch falsche Informationen. |
| Hybrid-Ansatz | Gezielte Kombination verschiedener KI-Modelle und Technologien für unterschiedliche Aufgaben. |
| IDE | Integrated Development Environment – Software, in der Programmierer Code schreiben und testen. |
| Inferenz | Der Vorgang, wenn ein trainiertes KI-Modell eine Eingabe verarbeitet und ein Ergebnis liefert. |
| Interoperabilität | Fähigkeit verschiedener Systeme, nahtlos zusammenzuarbeiten. |
| Iterativ | Schrittweises Vorgehen in wiederholten Durchläufen mit kontinuierlicher Verbesserung. |
| KI-Modell | Spezialisiertes Computerprogramm, das aus Daten lernt, Muster erkennt und Vorhersagen trifft. |
| Klassifikation | Automatische Zuordnung von Daten in vordefinierte Kategorien. |
| Kontextfenster | Maximale Textmenge, die ein KI-Modell gleichzeitig verarbeiten kann. Gemessen in Tokens. |
| KPI | Key Performance Indicator – Kennzahl zur Messung des Erfolgs. |
| Latenz | Zeitverzögerung zwischen Anfrage und Antwort eines KI-Systems. |
| LLM | Large Language Model – Großes Sprachmodell mit Milliarden Parametern (z. B. ChatGPT, Claude). |
| Machine Learning | Überbegriff für Verfahren, bei denen Computer aus Daten lernen. |
| Mixture of Experts | KI-Architektur mit mehreren spezialisierten Teilmodellen, die je nach Anfrage aktiviert werden. |
| Multi-Agenten-System | System, in dem mehrere spezialisierte KI-Agenten eigenständig zusammenarbeiten. |
| Multimodal | KI, die verschiedene Datentypen (Text, Bild, Audio, Video) gleichzeitig verarbeiten kann. |
| MVP | Minimum Viable Product – einfachste funktionsfähige Version eines Produkts. |
| NER | Named Entity Recognition – automatische Erkennung benannter Entitäten in Texten. |
| Neuronales Netz | Mathematische Struktur, lose vom Gehirn inspiriert, die Informationen in Schichten verarbeitet. |
| On-Premises | Software auf eigenen Servern im Unternehmen – volle Datenkontrolle, höhere Kosten. |
| Open Source | Software mit frei zugänglichem Quellcode (z. B. Llama, Stable Diffusion). |
| Overengineering | Einsatz einer unnötig komplexen Lösung für ein einfaches Problem. |
| Parameter | Die „Steuerknöpfe" eines KI-Modells, die während des Trainings eingestellt werden. |
| Pipeline-Ansatz | Kette aufeinanderfolgender Verarbeitungsschritte. |
| Prompt Engineering | Kunst, Eingaben an KI-Modelle so zu formulieren, dass möglichst gute Ergebnisse entstehen. |
| RAG | Retrieval Augmented Generation – LLM verbunden mit externer Wissensdatenbank. |
| Reasoning | Fähigkeit eines KI-Modells, logisch zu schlussfolgern. |
| ROI | Return on Investment – Rendite einer Investition. |
| Routing-Layer | Steuerungsschicht, die Anfragen automatisch an das passende KI-Modell weiterleitet. |
| Semantische Suche | Suche basierend auf Bedeutung statt exakten Stichworten. |
| Sentiment-Analyse | Automatische Erkennung von Stimmungen und Emotionen in Texten. |
| Skalierbarkeit | Fähigkeit eines Systems, bei steigender Nutzung leistungsfähig zu bleiben. |
| SLM | Small Language Model – Kleines Sprachmodell, schneller und günstiger als LLMs. |
| Token | Kleinste Verarbeitungseinheit eines Sprachmodells. Ein deutsches Wort benötigt 1–3 Tokens. |
| Vendor Lock-in | Abhängigkeit von einem bestimmten Anbieter, die den Wechsel schwierig oder teuer macht. |
| Zero-Shot Learning | Fähigkeit, eine Aufgabe ohne jegliches Beispiel zu lösen. |
